








































近日,国内云主机商阿里云重磅开源新版通义千问Qwen3系列模型,Qwen3-Embedding和Qwen3-Reranker。该系列模型专为文本表征、检索与排序任务设计,基于Qwen3基础模型进行训练。
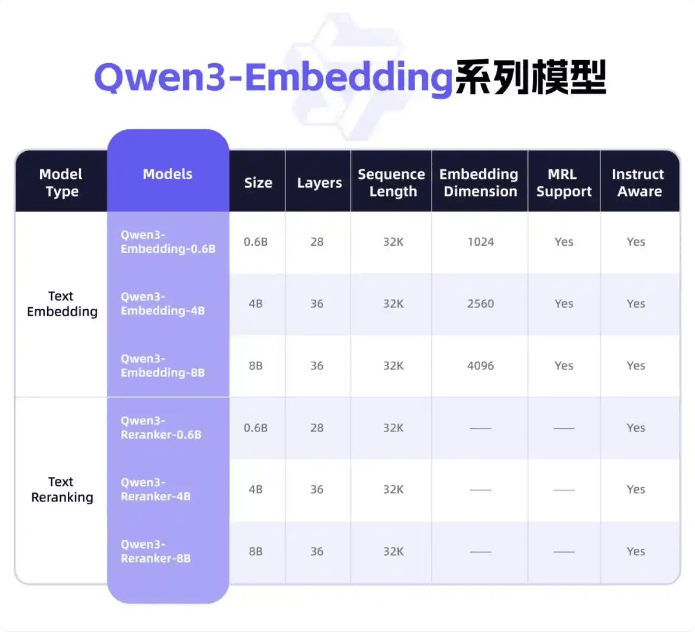
据悉,在多项基准测试中,这两款模型表征和排序任务中展现了卓越的性能;在模型架构方面,这两款模型采用了基于Qwen3基础模型的密集版本,并提供了三种不同参数规模的模型配置,分别是0.6B、4B和8B参数,以满足不同场景下的性能与效率需求。
阿里云此次重磅开源新版Qwen3系列模型具备如下特点:
1、卓越的泛化性
新版通义千问Qwen3系列模型在多个下游任务评估中达到行业领先水平。其中,8B参数规模的Embedding模型在MTEB多语言Leaderboard榜单中位列第一(截至2025年6月6日,得分70.58),性能超越众多商业API服务。此外,该系列的排序模型在各类文本检索场景中表现出色,显著提升了搜索结果的相关性。
2、灵活的模型架构
新版通义千问Qwen3系列模型提供从0.6B到8B参数规模的3种模型配置,以满足不同场景下的性能与效率需求。开发者可以灵活组合表征与排序模块,实现功能扩展。
3、全面的多语言支持
新版通义千问Qwen3系列模型支持超过100种语言,涵盖主流自然语言及多种编程语言。该系列模型具备强大的多语言、跨语言及代码检索能力,能够有效应对多语言场景下的数据处理需求。
为了使模型能够更好地遵循指令,在下游任务中表现出色,研究人员将指令与查询文本拼接为单一输入上下文,而文档保持不变。这种设计使得模型能够更好地理解和处理复杂的语义任务,提升了模型在多语言和跨语言任务中的表现。
对于排序模型,采用了单塔结构,将文本对(如用户查询与候选文档)作为输入,并通过大模型的对话模板将相似性评估任务转化为二分类问题。模型能根据输入的指令、查询和文档,判断文档是否符合查询要求,并输出相关性得分。这种设计使得模型能够更加精准地评估文本对之间的相关性,从而在排序任务中取得更好的效果。
在训练范式方面,该系列模型采用了创新的多阶段训练方法,包括大规模无监督预训练、高质量数据的监督微调以及模型融合策略。
在无监督预训练阶段,研究人员利用Qwen3基础模型的文本生成能力,合成大规模的弱监督训练数据。这些数据涵盖了多种任务类型、语言和领域,为模型提供了广泛的学习素材。这种合成数据的方法不仅提高了数据的可控性,还能够在低资源语言和领域中生成高质量的数据,突破了传统方法依赖社区论坛或开源数据筛选获取弱监督文本对的局限性,实现了大规模弱监督数据的高效生成。
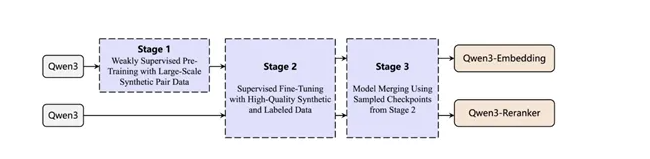
在监督微调阶段,研究人员选择了高质量的小规模标注数据进行训练,进一步提升模型的性能。这一阶段的训练数据不仅包括开源的标注数据集,例如,MS MARCO、NQ、HotpotQA等,还筛选了部分合成数据。通过简单的余弦相似度计算,从合成数据中筛选出高质量的数据对,进一步提升模型的性能。这种策略不仅提高了模型的泛化能力,还在多种基准测试中取得了优异的成绩。
最后,在模型融合阶段,研究人员采用了基于球面线性插值的模型融合技术。通过合并微调过程中保存的多个模型检查点,模型能够在不同数据分布上表现出更好的性能。这一策略显著提升了模型的稳定性和一致性,增强了模型的鲁棒性和泛化能力。



