








































近日,国内著名社交平台小红书重磅开源首个大模型dots.llm1,该模型为1420亿参数专家混合模型(MoE),推理仅激活140亿参数,这种结构不仅保持了高性能,还大幅降低了训练和推理的成本。
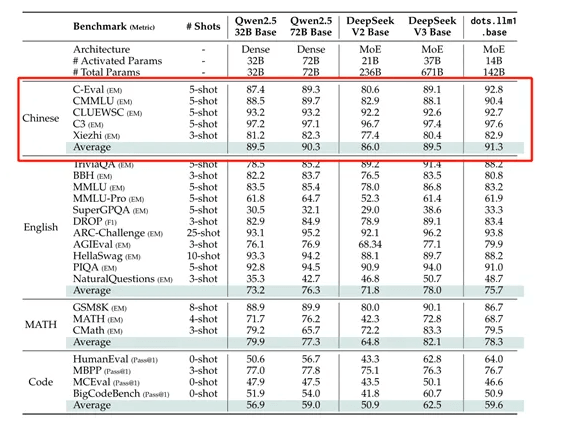
dots.llm1最大特色是使用了11.2万亿token的非合成高质量训练数据,这在现阶段的开源大模型中非常罕见。所以,在中文测试中dots.llm1的性能非常强,以91.3的平均分超过了DeepSeek开源的V2、V3和阿里开源的Qwen2.5 32B和72B。
dots.llm1模型采用了decoder-only的Transformer架构,每一层都包含一个注意力层和前馈网络(FFN)。与Llama或Qwen等密集型模型不同,FFN被替换为MoE模块。这种修改使其能够在保持经济成本的同时训练出能力强大的模型。
MoE将模型分为多个专家网络,每个专家网络专注于输入数据的不同方面。在推理过程中,并不激活所有的专家网络,而是根据输入标记的特性,动态地选择一小部分专家网络进行计算。这种稀疏激活的方式极大减少了算力的需求,同时保持了模型的高性能。
具体来说,dots.llm1包含128个路由专家和2个共享专家。每个专家都是一个具有两层前馈结构的网络,使用SwiGLU激活函数以捕捉数据中的复杂关系。在处理输入标记时,模型会动态选择出6个最相关的专家和2个共享专家进行运算。
dots.llm1在训练过程中还引入了改进的RMSNorm归一化操作,以稳定模型性能和输出。在MoE模块中,负载平衡策略的引入确保了所有专家网络的使用均衡,从而避免了过度依赖某些专家的问题。
在MoE模块中,dots.llm1还引入了无辅助损失的负载平衡策略。负载平衡是MoE架构中的一个关键问题,因为如果专家网络之间的负载不平衡,会导致一些专家网络被过度使用,而另一些专家网络则很少被激活。这种不平衡不仅会影响模型的性能,还会降低计算效率。dots.llm1通过引入一个动态调整的偏置项来解决这个问题。偏置项会根据每个专家网络的负载情况动态调整,从而确保所有专家网络的负载相对平衡,不仅能够有效地解决负载不平衡的问题,而且不会引入额外的损失函数,从而避免了对模型性能的负面影响。
为了提升模型的训练效率,dots.llm1还使用了AdamW优化器,这一优化算法能有效防止模型过拟合并控制梯度爆炸。
此外,在数据处理上,dots.llm1一共使用了11.2万亿token非合成数据,并构建了一套三级数据处理流水线,从杂乱无章的原始网页数据中筛选出高质量的语料。

