







































-


腾讯云开源最新混元大模型Hunyuan-A13B
最近,国内云服务器商腾讯云宣布开源最新混元大模型Hunyuan-A13B。该模型总参数为80B,但激活参数仅为13B,以小参数实现了比肩同等架构领先开源模型的成绩,具有推理速度更快,性价比更高的优势。 目前该模型已经在Github和Huggingface等开源社区上线,同时模型API也在腾讯云官网正式上线,支持快速接入部署。 腾讯云官网:点击进入 据悉,Hunyuan-A13B是腾讯内部应用和调用…...- 0
- 11
-

Alist完美平替Openlist上线
开源网盘Alist被收购以后,让很多用户都开始焦虑起来。此时,Openlist作为一款非常完美的替代方案进入了人们的视野,该软件是由原Alist核心团队成员发起的,吸取了Alist的优点,并在某些方面进行了创新,力求为用户提供更稳定、更自由的选择。 Alist作为一个优秀的开源项目,凭借其强大的文件列表功能和便捷的分享能力,赢得了众多用户的喜爱。但是前段时候已经被收购,并且存在着数据安全、功能延续…...- 0
- 36
-
月之暗面开源并升级多模态大模型Kimi-2506
最近,月之暗面对其开源的多模态模型Kimi-VL-A3B-Thinking进行了大升级,发布了2506版本,该版本的发布标志着智能体和视觉理解技术的重大进步。 在多模态推理基准测试中,Kimi-VL-A3B-Thinking-2506取得了更好的准确性:MathVision上达到56.9(提升20.1),MathVista上为80.1(提升8.4),MMMU-Pro上是46.3(提升3.2),MM…...- 0
- 19
-
OpenAI开源最新客户服务AI Agent
近日,OpenAI发布了一款新的开源演示程序,让开发者能够亲身体验如何使用Agents SDK构建智能、工作流程感知的智能体。 OpenAI此次开源的新客户服务智能体(AI Agent)没有限制,任何第三方开发者或用户都可以免费获取、修改并部署该代码,用于其自身的商业或实验目的。 相关推荐: 《智能体是什么东西》 《什么是AI Agent AI Agent能干啥》 这个AI Agent模拟了一个…...- 0
- 13
-


开源网盘Alist疑似被收购 中文文档被大规模修改
开源网盘Alist作为一款超火的开源网盘,不仅支持多种网盘的挂载,还因其简洁的前端界面和强大的API接口被誉为“资源管理神器”,在Github上已经有49.8K Star,一直以来都有着极高的口碑。近期,Alist疑似被“贵州不够科技”收购,中文文档已经被大幅度修改,还新增了多个QQ群和所谓的VIP技术支持渠道,引发了广泛关注。 Alist是一个开源项目,轻量且功能强大,可以将阿里云盘、百度网盘、…...- 0
- 21
-
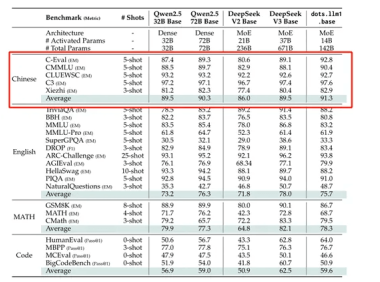
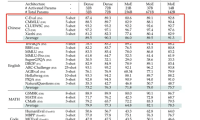
小红书重磅开源首个大模型dots.llm1
近日,国内著名社交平台小红书重磅开源首个大模型dots.llm1,该模型为1420亿参数专家混合模型(MoE),推理仅激活140亿参数,这种结构不仅保持了高性能,还大幅降低了训练和推理的成本。 dots.llm1最大特色是使用了11.2万亿token的非合成高质量训练数据,这在现阶段的开源大模型中非常罕见。所以,在中文测试中dots.llm1的性能非常强,以91.3的平均分超过了DeepSeek开…...- 0
- 32
-
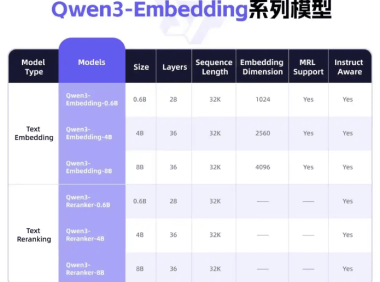
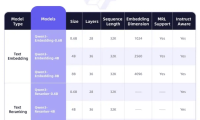
阿里云重磅开源新版Qwen3系列模型
近日,国内云主机商阿里云重磅开源新版通义千问Qwen3系列模型,Qwen3-Embedding和Qwen3-Reranker。该系列模型专为文本表征、检索与排序任务设计,基于Qwen3基础模型进行训练。 据悉,在多项基准测试中,这两款模型表征和排序任务中展现了卓越的性能;在模型架构方面,这两款模型采用了基于Qwen3基础模型的密集版本,并提供了三种不同参数规模的模型配置,分别是0.6B、4B和8B…...- 0
- 20
-

OpenAI宣布ChatGPT推出会议记录模式并支持MCP协议
近日,OpenAI在技术直播中对ChatGPT进行了重大更新,包括向macOS用户推出ChatGPT会议记录模式,可以转录任何会议、头脑风暴或语音笔记,并快速提取要点然后转化为新的内容。另外一个重要功能就是ChatGPT正式支持MCP协议,例如,直接连接Github、SharePoint、Gmail、Dropbox、Box、Outlook等常用工具,实现跨平台数据整合、搜索和推理。这一系列措施标志…...- 0
- 27
-
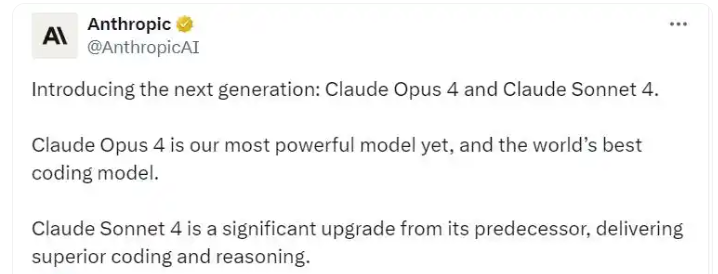

Anthropic发布最新大模型Claude 4 可连续工作7小时
著名大模型平台Anthropic在首届开发者大会中发布了最新大模型Claude 4。据Anthropic介绍称,Claude Opus 4是“世界上最好的编码模型”,可以像人类一样完成一个几乎完整的工作班次(7小时)。 Claude 4又分为两个版本,分别为Claude Opus 4和Claude Sonnet 4。这两个模型的设计都是为了更好地遵循指令,并在处理诸如编写代码和回答复杂问题等任务时…...- 0
- 33
-


OpenAI推出的Responses API支持MCP服务
近日,OpenAI宣布其Responses API支持MCP服务,开发者无需为每个函数调用手动连接特定服务,而是可以将模型配置为指向一个或多个MCP服务。 Responses API是OpenAI推出的最新核心API,旨在简化开发者与AI交互的方式,并扩展其功能。它是Chat Completions API的升级版本,结合了Chat Completions的简洁性和Assistants API的强…...- 0
- 31
-
微软正式开源Windows子系统WSL
最近,微软宣布开源适用于Linux的Windows子系统——WSL。WSL(Windows Subsystem for Linux)是微软在2016年发布的一项重磅功能,可在Windows操作系统上运行Linux环境,而无需单独的虚拟机或双引导。此外,还能快速安装各种Linux版本软件。 目前WSL系统已经支持包括DeepSeek在内的一些热门大模型。 WSL最早在2016年的微软BUILD大会上…...- 0
- 44
-


DeepSeek发布超强开源模型V3最新论文
最近,DeepSeek团队发布了一篇围绕DeepSeek-V3的技术论文,名为《Insights into DeepSeek-V3:Scaling Challenges and Reflections on Hardware for Al Architectures(深入了解DeepSeek-V3:人工智能架构硬件的扩展挑战与思考)》。在论文中,团队把DeepSeek-V3在训练和推理过程中,如何…...- 0
- 39





















