全球著名大模型开源平台DeepSeek正式开源了Deepseek V3.1-Base模型,该模型是DeepSeek-V3系列最新的基础模型,将上下文长度扩展至128K,参数规模约为685B,展现出更强的长文本处理能力。
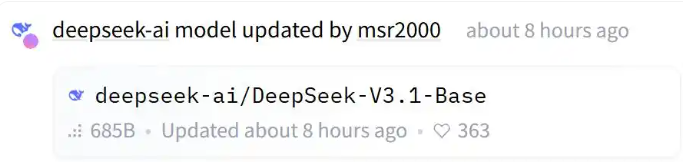
在Hugging Face上发布了DeepSeek-V3.1-Base模型以后,短短几个小时就已经冲上了Hugging Face热门模型榜第4位。
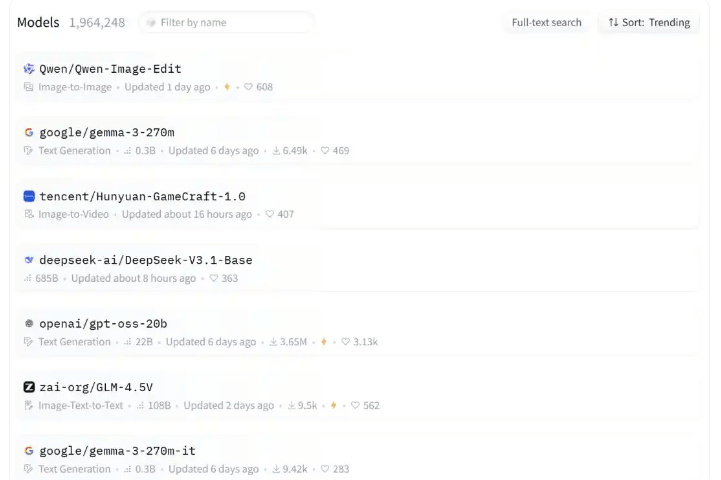
由上图可以看出,排在第一位的是阿里云通义千问团队开源语言模型系列,第二位是谷歌推出的大模型,第三位是腾讯混元大模型,第四位正是DeepSeek此次开源的最新模型。
本次开源的DeepSeek-V3.1-Base模型拥有685B参数,支持多种精度格式,从BF16到FP8。以下是本文整理的几大亮点:
- 编程能力:表现突出,根据社区使用Aider测试数据,V3.1在开源模型中霸榜。
- 性能突破:V3.1在Aider编程基准测试中取得71.6%高分,超越Claude Opus 4,同时推理和响应速度更快。
- 原生搜索:新增了原生search token的支持,这意味着搜索的支持更好。
- 架构创新:线上模型去除R1标识,分析称DeepSeek未来有望采用混合架构。
- 成本优势:每次完整编程任务仅需1.01美元,成本仅为专有系统的六十分之一。
DeepSeek发布通知称,线上模型版本已升级至V3.1,上下文长度拓展至128k,可通过官方网页、App、小程序测试,API接口调用方式保持不变。