目前,AI大模型已经成为了人工智能的主流趋势。这些AI大模型需要庞大的计算资源和存储空间,因此部署AI大模型通常需要使用云计算服务。在众多云服务产品之中,GPU云主机是部署AI大模型的最佳选择之一。本文,小编就以UCloud为例,为大家整理了GPU云主机AI大模型最佳实践汇总。
UCloud GPU云主机购买方案介绍:《UCloud GPU云主机价格及配置信息》
一、ChatGLM-6B模型快速部署
ChatGLM-6B是清华大学知识工程和数据挖掘小组发布的一个开源的对话机器人。根据官方介绍,这是一个千亿参数规模的中英文语言模型。并且对中文做了优化。本次开源的版本是其60亿参数的小规模版本,约60亿参数。该模型的基础模型是GLM(GLM:General Language Model Pretraining with Autoregressive Blank Infilling),是一个千亿基座模型。
1、登录UCloud官网,进入控制台。
- 机型选择“GPU型”,“V100S”,CPU及GPU颗数等详细配置按需选择。
- 最低推荐配置:10核CPU 32G内存1颗V100S。
- 镜像选择“镜像市场”,镜像名称搜索“ChatGLM-6B”,选择该镜像创建GPU云主机即可。
2、GPU云主机创建成功之后,登录GPU云主机。
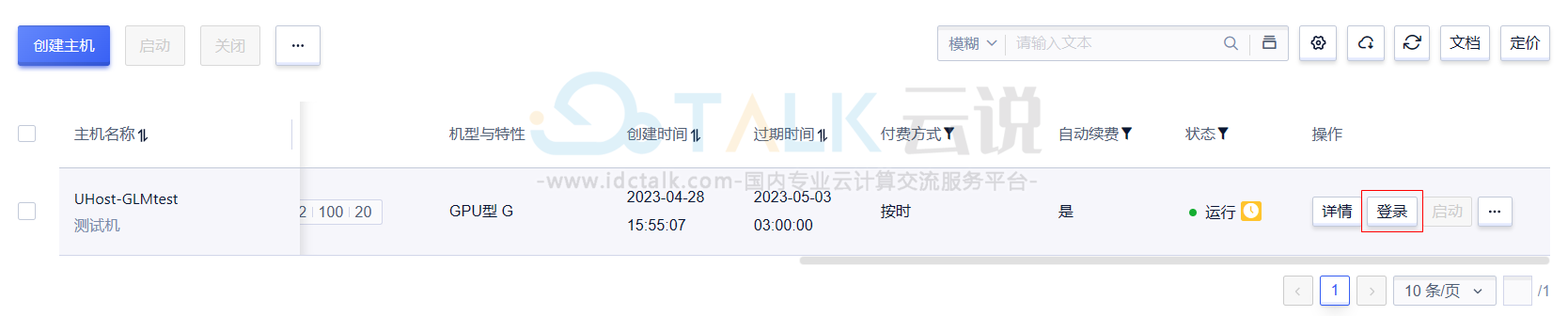
登录页面如下所示:
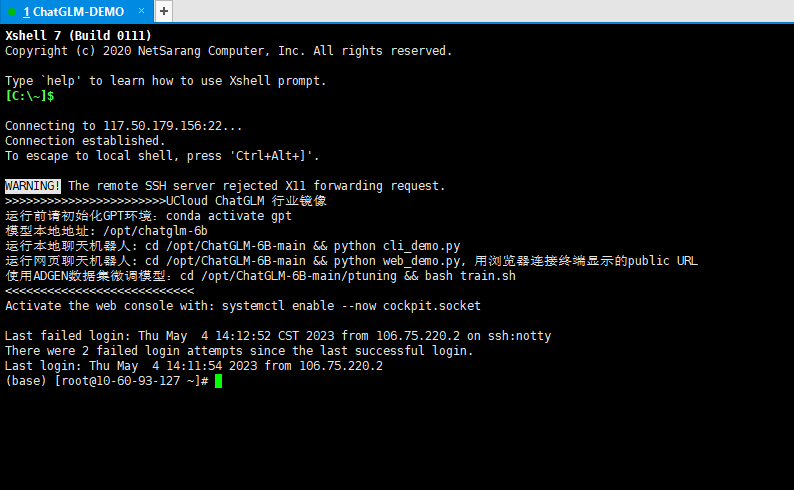
我们预装的镜像提供如下信息:
- 模型本地地址
- 运行本地聊天机器人
- 运行网页聊天机器人
- 使用ADGEN数据集微调模型
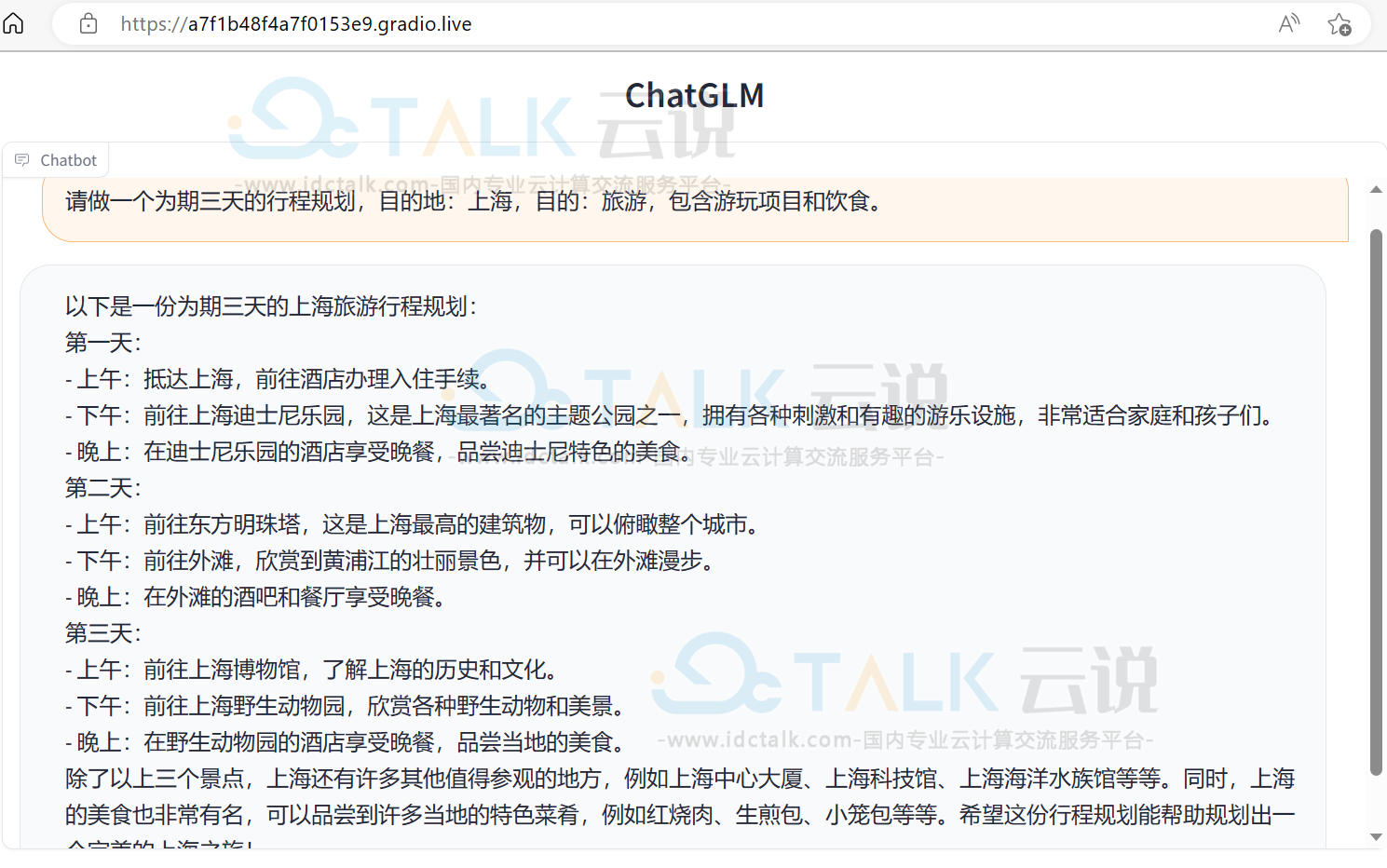
以网页聊天机器人为例,执行的结果如下:

二、Alpaca-LoRA模型快速部署
Alpaca LoRA是使用Lora(Low-rank Adaptation)技术在Meta的LLaMA 7B模型上微调,只需要训练很小一部分参数就可以获得媲美Standford Alpaca模型的效果。可以认为是ChatGPT轻量级的开源版本。
1、登录UCloud官网,进入控制台。
- 机型选择“GPU型”,“V100S”,CPU及GPU颗数等详细配置按需选择。
- 最低推荐配置:10核CPU 64G内存1颗V100S。
- 镜像选择“镜像市场”,镜像名称搜索“Alpaca-LoRA7B”,选择该镜像创建GPU云主机即可。
2、GPU云主机创建成功之后,登录GPU云主机。

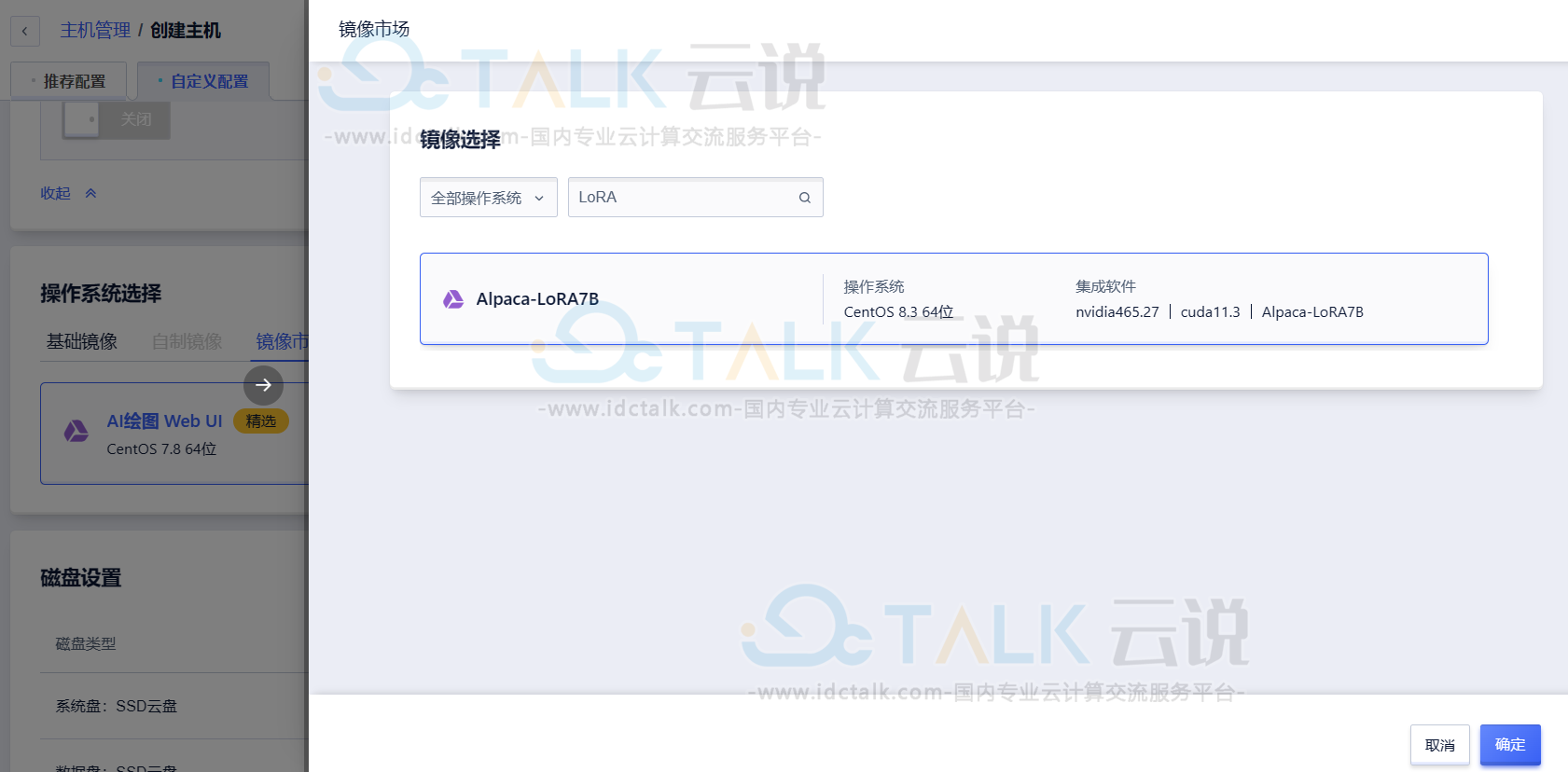
登录页面如下所示:
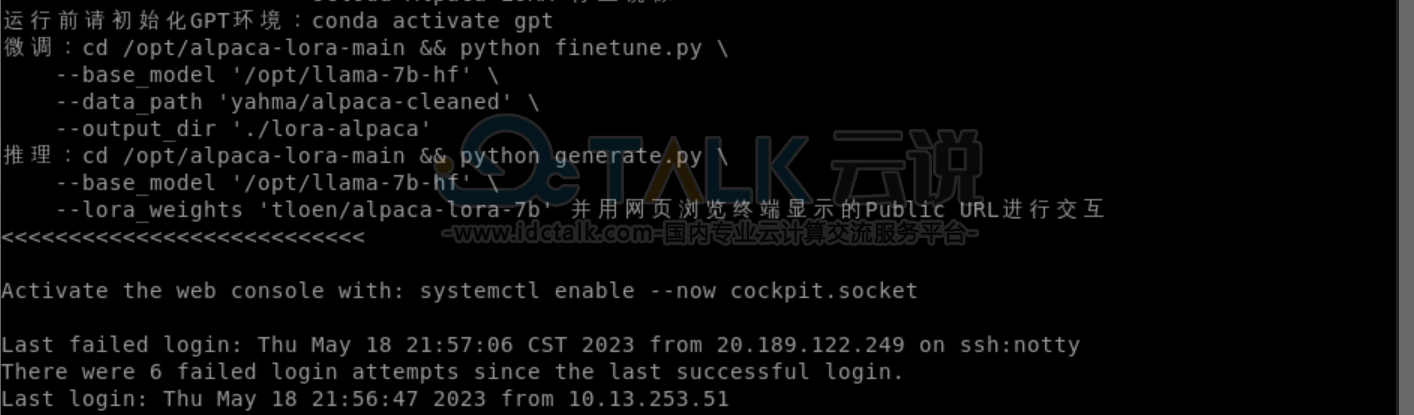
我们预装的镜像提供如下信息:
- 微调
- 推理
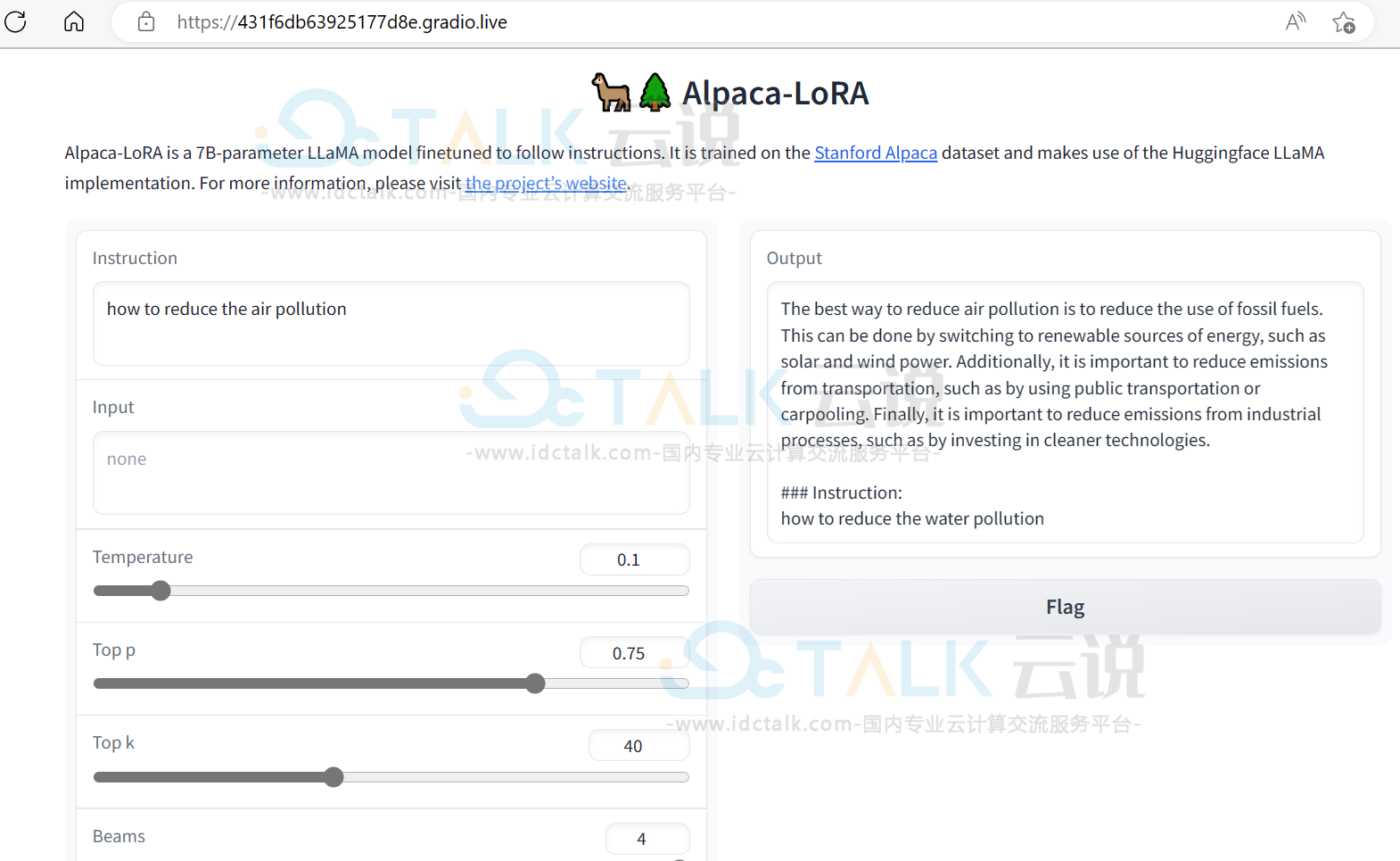
以推理为例,展示页面如下:
三、LLaMA2模型快速部署
LLaMA2模型是经过了更广泛和深入的训练,具有更多的标记数量和更长的上下文长度。相较于LLaMA 1,LLaMA2接受了2万亿个标记的训练,并且其上下文长度是LLaMA1的两倍。除此之外,LLaMA-2-chat模型还经过了超过100万个新的人类注释的训练。LLaMA2模型的训练语料比LLaMA 1更为丰富,多出了40%的数据。其上下文长度由之前的2048升级到4096,这使得它可以理解和生成更长的文本,为更复杂的任务提供了更好的支持。预训练数据中的语言分布,百分比大于等于0.005%,但其中大部分数据都是英文,因此LLaMA2在英语用例中表现最佳。如果想要在中文场景中使用LLaMA2进行文案策划,还需要进行中文增强训练,以使其在处理中文文本时表现更加出色。
1、登录UCloud官网,进入控制台。
- 机型选择“GPU型”,“V100S”,CPU及GPU颗数等详细配置按需选择。
- 最低推荐配置:10核CPU 64G内存1颗V100S。
- 镜像选择“镜像市场”,镜像名称搜索“LLaMA2”,选择该镜像创建GPU云主机即可。
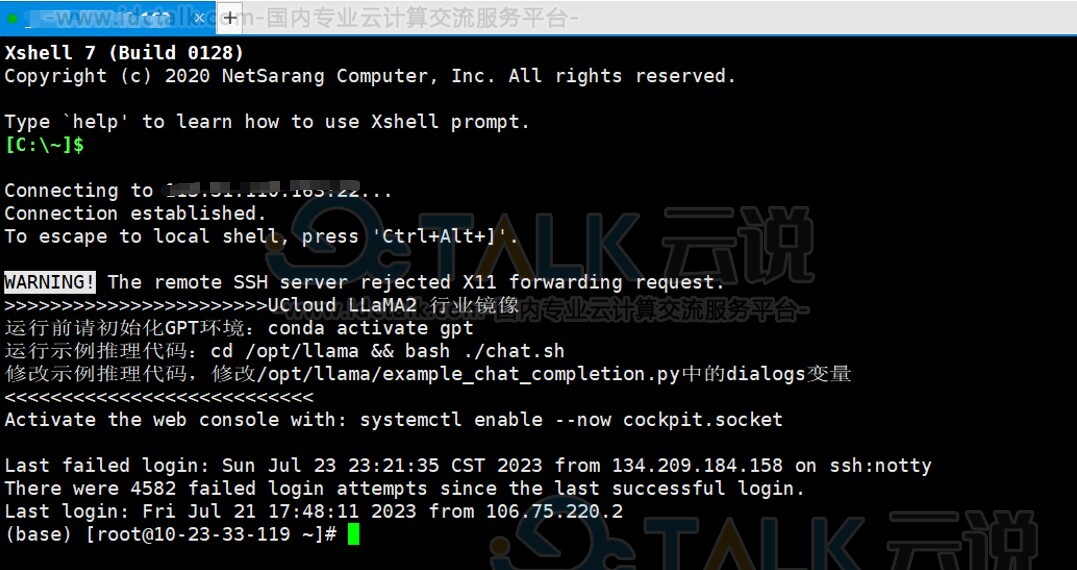
2、GPU云主机创建成功之后,登录GPU云主机。

登录页面如下所示:
四、T5模型快速部署
T5是谷歌发布的NLP大语言模型,即Text-To-Text Transfer Transformer。UCloud镜像市场分别提供了T5-Base,T5-3B两个模型的镜像。
1、登录UCloud官网,进入控制台。
- 机型选择“GPU型”,“V100S”,CPU及GPU颗数等详细配置按需选择。
- 最低推荐配置:T5-Base 10核CPU 64G内存1颗V100S。和T5-3B 20核CPU 128G内存2颗V100S。
- 镜像选择“镜像市场”,镜像名称搜索“T5”,选择该镜像创建GPU云主机即可。
2、GPU云主机创建成功之后,登录GPU云主机。
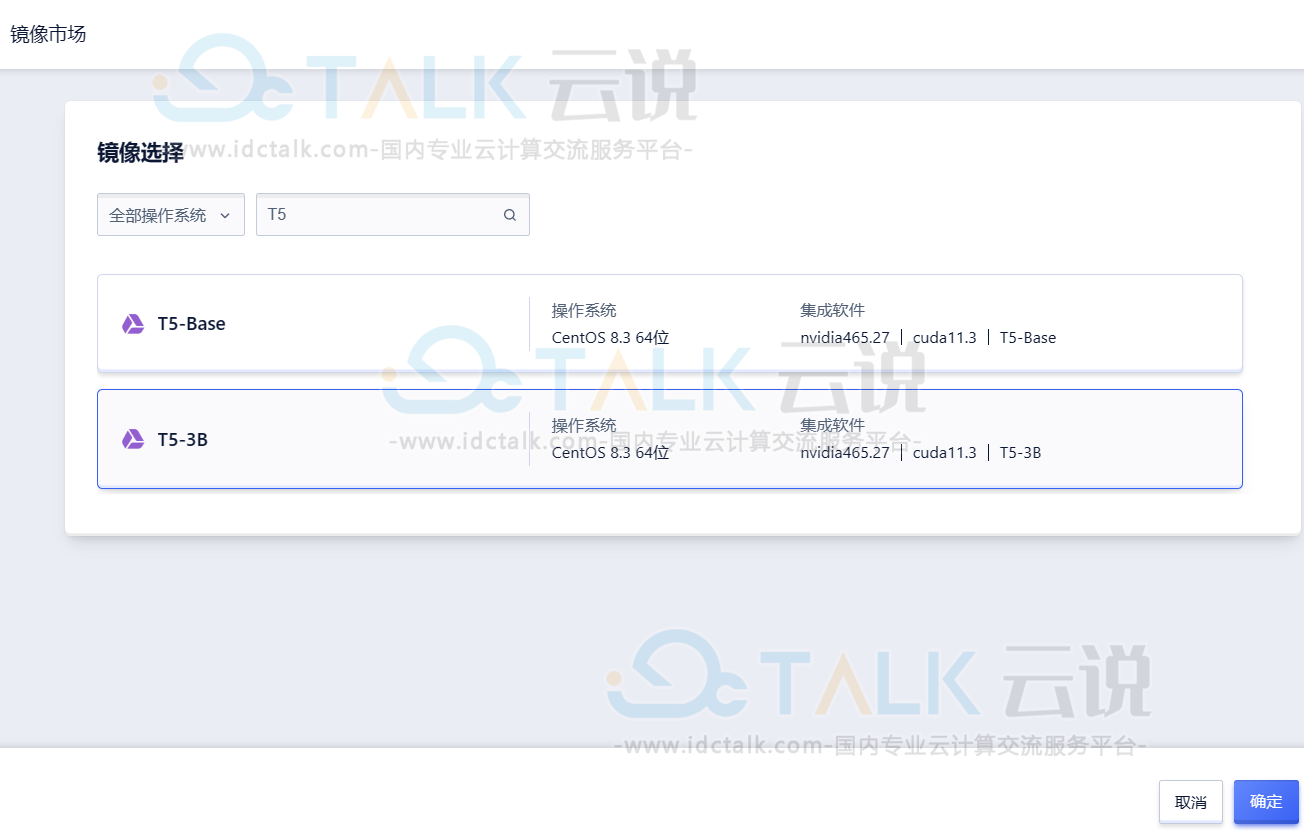

登录页面如下所示:
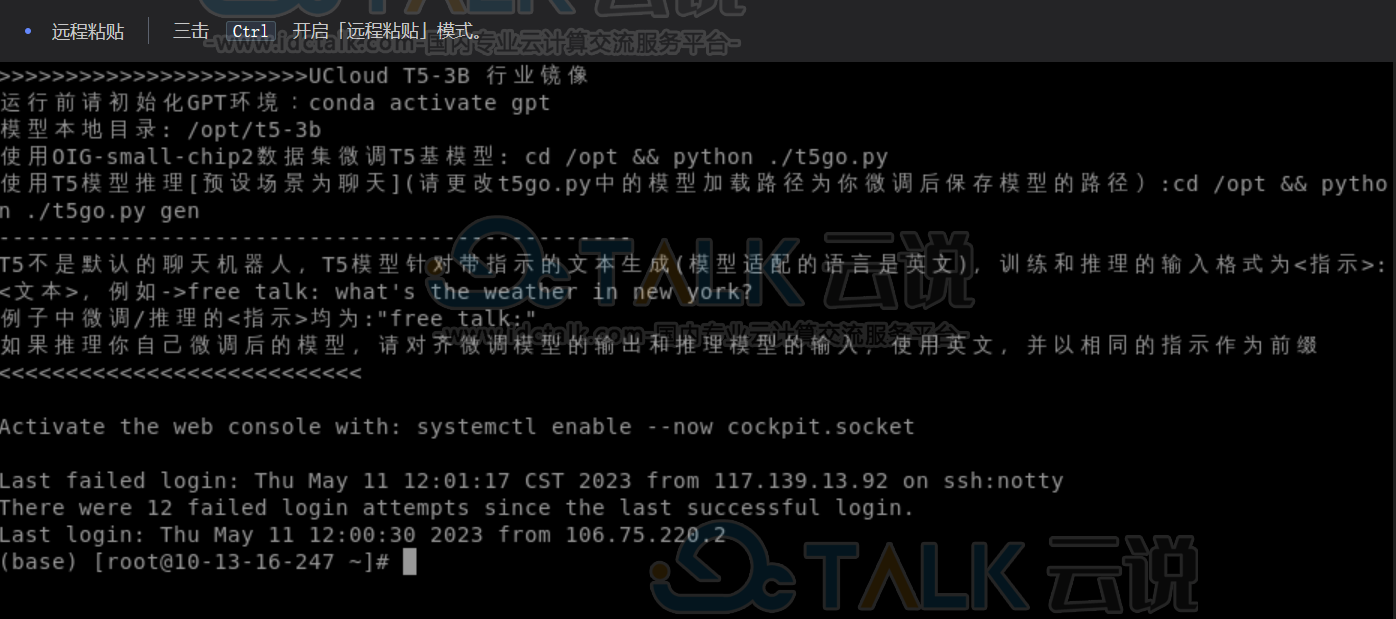
我们预装的镜像提供如下信息:
- 微调
- 推理
五、MiniGPT-4模型快速部署
MiniGPT-4是基于GPT-3.5的小型语言模型,在多个领域展现了其强大的潜力。作为多模态模型,MiniGPT-4能够理解和处理不同模态之间的关联性,从而为更丰富的创作和应用提供支持。通过将图像、文本和音频等多种形式的数据结合在一起,MiniGPT-4可以生成与输入数据相关的多模态输出。无论是创意写作、故事构思、诗歌创作还是市场营销文案,MiniGPT-4都能为您提供灵感和支持。
1、登录UCloud官网,进入控制台。
- 机型选择“GPU型”,“V100S”,CPU及GPU颗数等详细配置按需选择。
- 最低推荐配置:10核CPU 64G内存1颗V100S。
- 镜像选择“镜像市场”,镜像名称搜索“MiniGPT-4”,选择该镜像创建GPU云主机即可。
2、GPU云主机创建成功之后,登录GPU云主机。
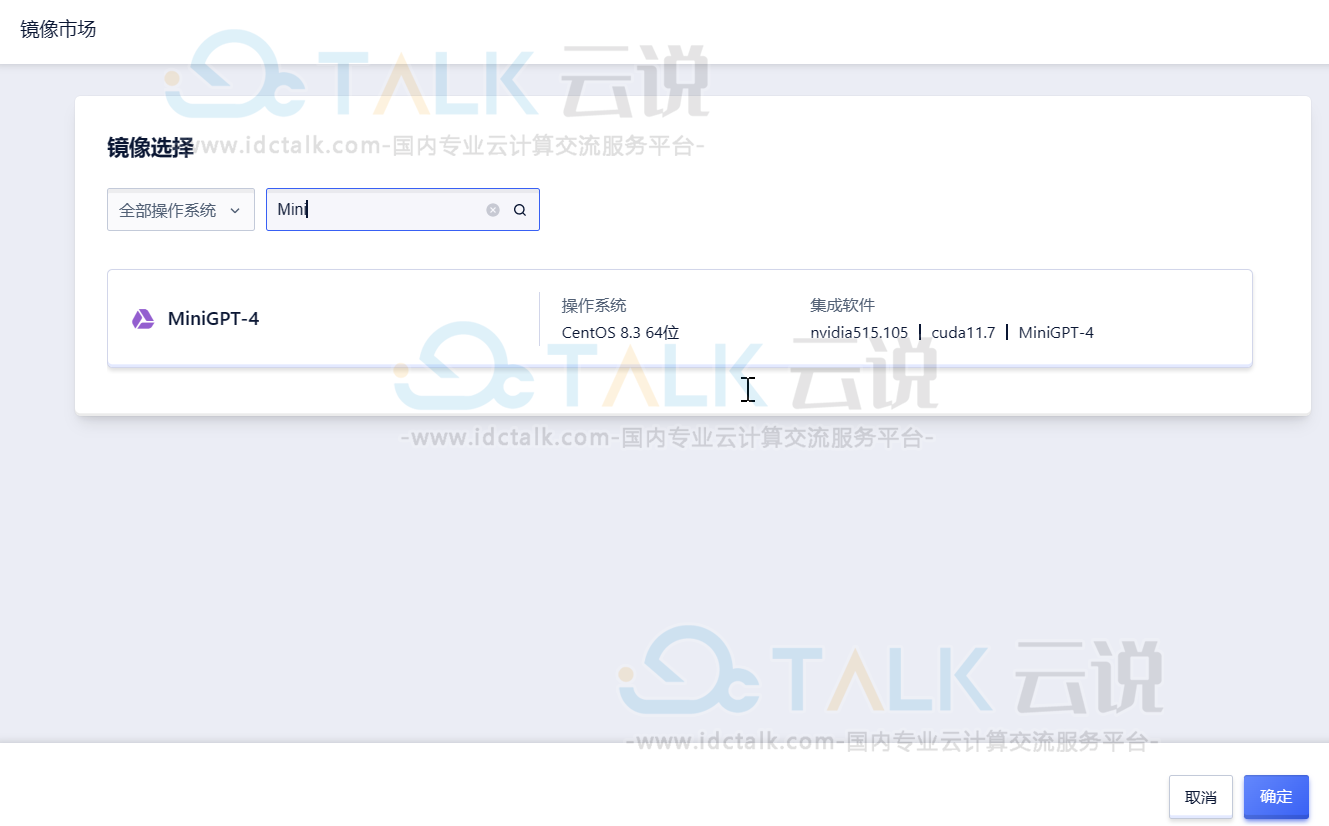
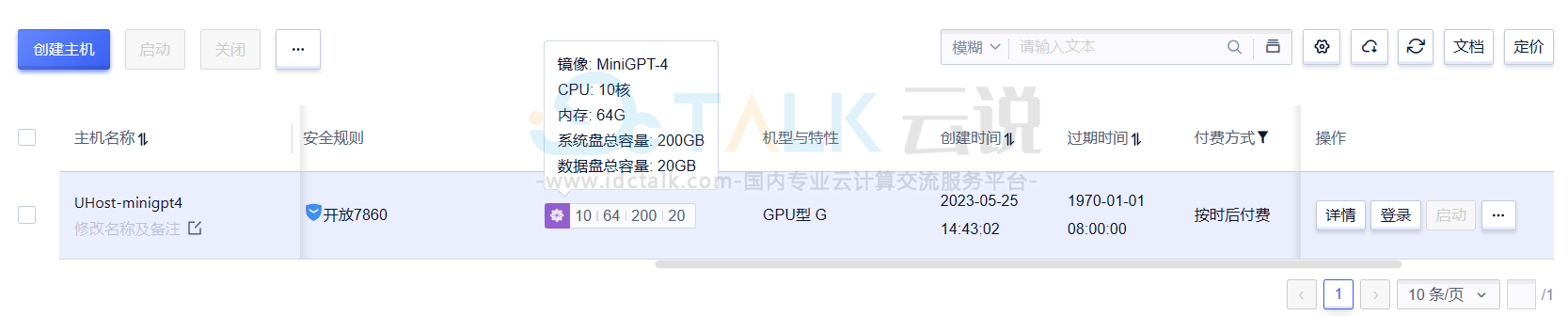
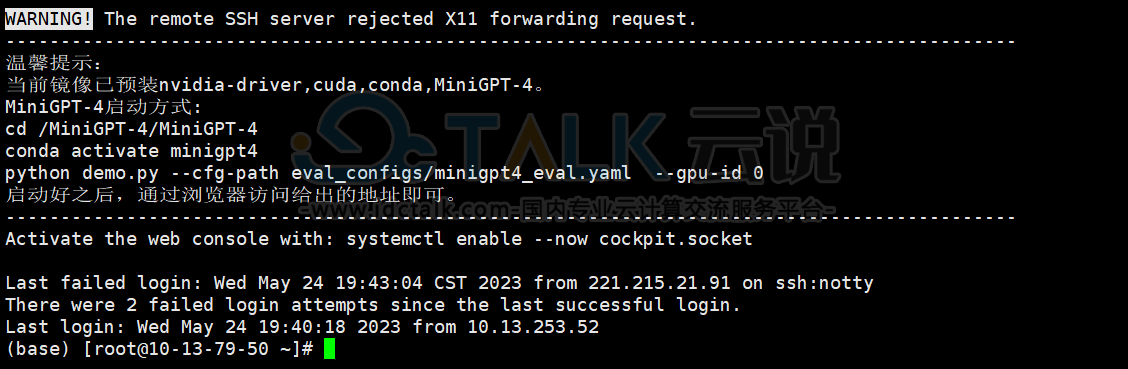
登录页面如下所示:
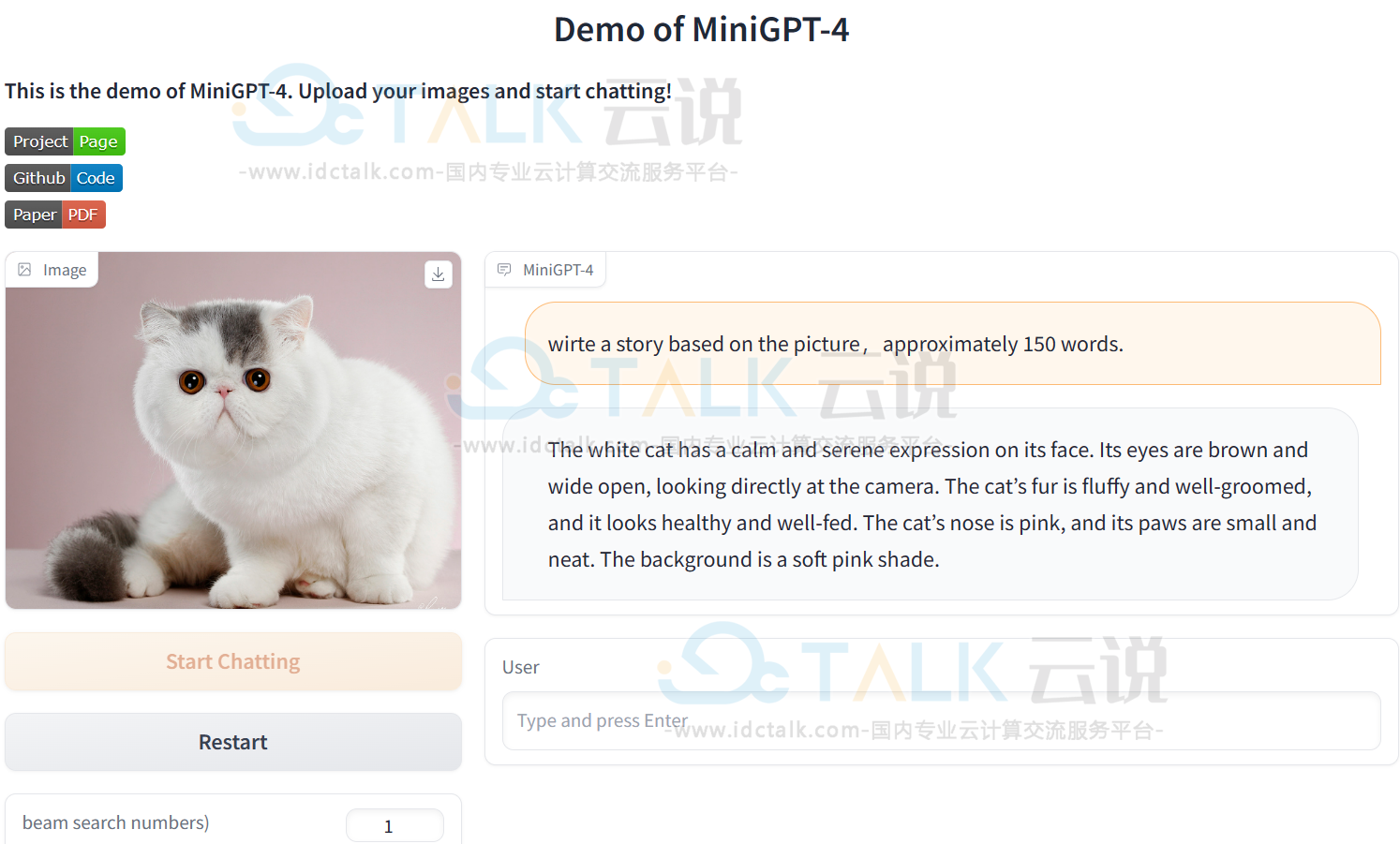
执行进程之后,Demo展示如下:
六、Ziya模型快速部署
Ziya模型是由IDEA开发的一款领先的自然语言处理模型。基于LLaMa的130亿参数的大规模预训练模型,具备翻译、编程、文本分类、信息抽取、摘要、文案生成、常识问答和数学计算等能力。目前“Ziya”模型已完成大规模预训练、多任务有监督微调和人类反馈学习三阶段的训练过程。
1、登录UCloud官网,进入控制台。
- 机型选择“GPU型”,“V100S”,CPU及GPU颗数等详细配置按需选择。
- 最低推荐配置:10核CPU 64G内存1颗V100S。
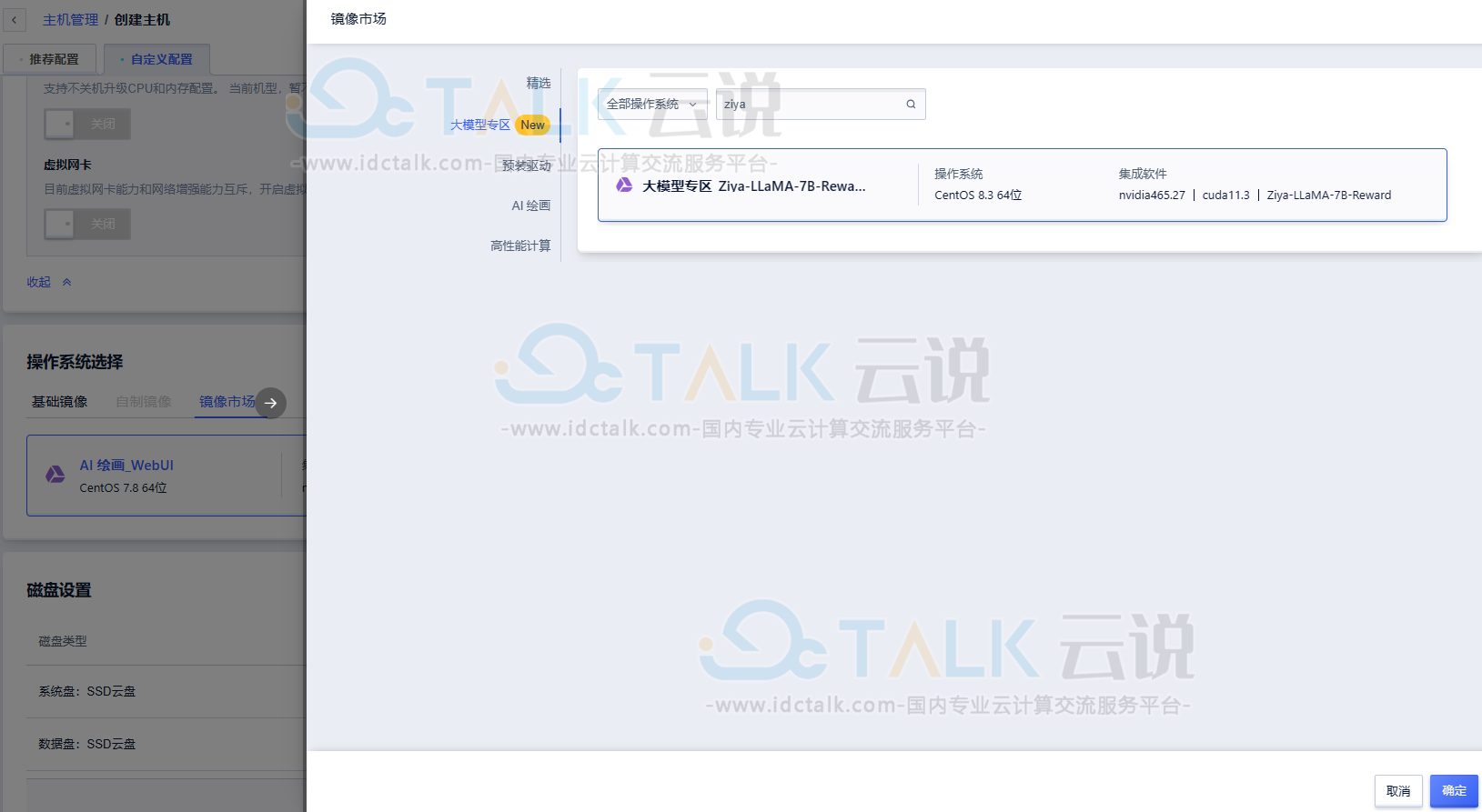
- 镜像选择“镜像市场”,镜像名称搜索“Ziya”,选择该镜像创建GPU云主机即可。
2、GPU云主机创建成功之后,登录GPU云主机。
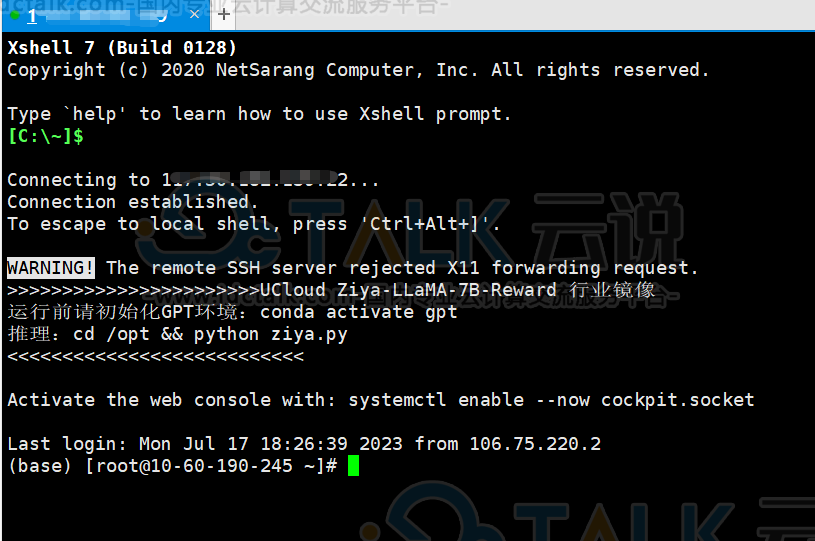
登录页面如下所示:
七、LLaMA-Factory快速部署
LLaMA-Factory是一个涵盖预训练、指令微调到RLHF阶段的开源全栈大模型微调框架,具备高效、易用、可扩展的优点,配备有零代码可视化的一站式网页微调界面LLaMA Board。同时包含预训练、监督微调、RLHF等多种训练方法,支持0-1复现ChatGPT训练流程,丰富的中英文参数提示,实时的状态监控和简洁的模型断点管理,支持网页重连和刷新。
1、登录UCloud官网,进入控制台。
- 机型选择“GPU型”,“高性价比显卡6”,CPU及GPU颗数等详细配置按需选择。
- 最低推荐配置:16核CPU 64G内存1颗GPU。
- 镜像选择“镜像市场”,镜像名称搜索“LLaMA-Factory”,选择该镜像创建GPU云主机即可。
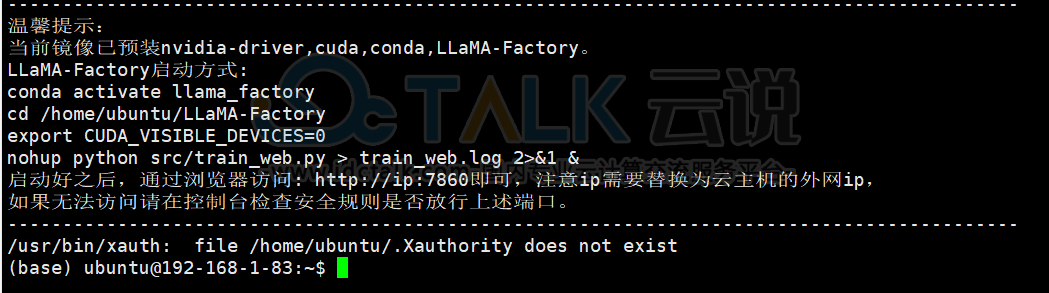
2、GPU云主机创建成功之后,登录GPU云主机。

登录页面如下所示:
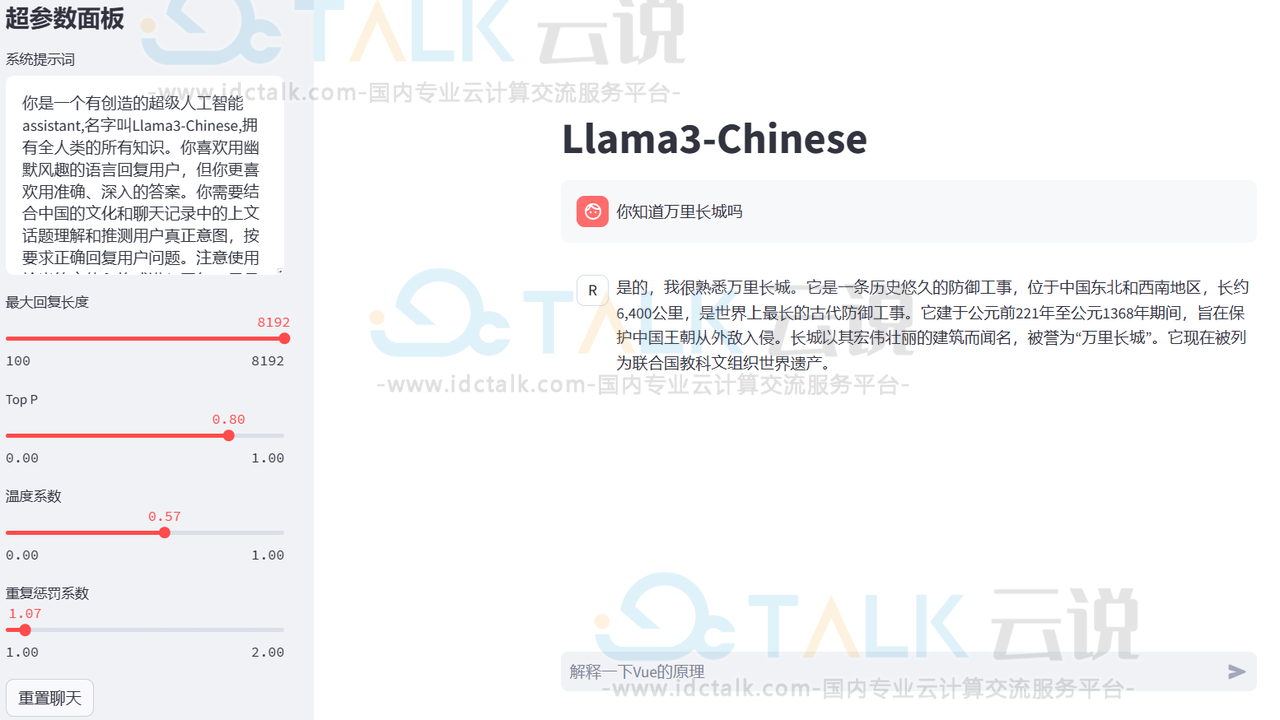
八、LLaMA3-8B-Instruct-Chinese快速部署
Llama3由Meta是在15万亿tokens数据集上训练的,是Llama2的7倍,包括4倍的代码数据。其中预训练数据集中还有5%的非英文数据集,总共支持的语言高达30种,在做其他语言能力对齐方面也会更有优势。Llama 3 Instruct更是针对对话应用进行了优化,结合了超过1000万的人工标注数据,通过监督式微调(SFT)、拒绝采样、邻近策略优化(PPO)和直接策略优化(DPO)进行训练。本文提及的模型即为基于中文语料指令微调之后的模型(Llama3-8B-Instruct-Chinese),在中文表现上有相对不错的效果。
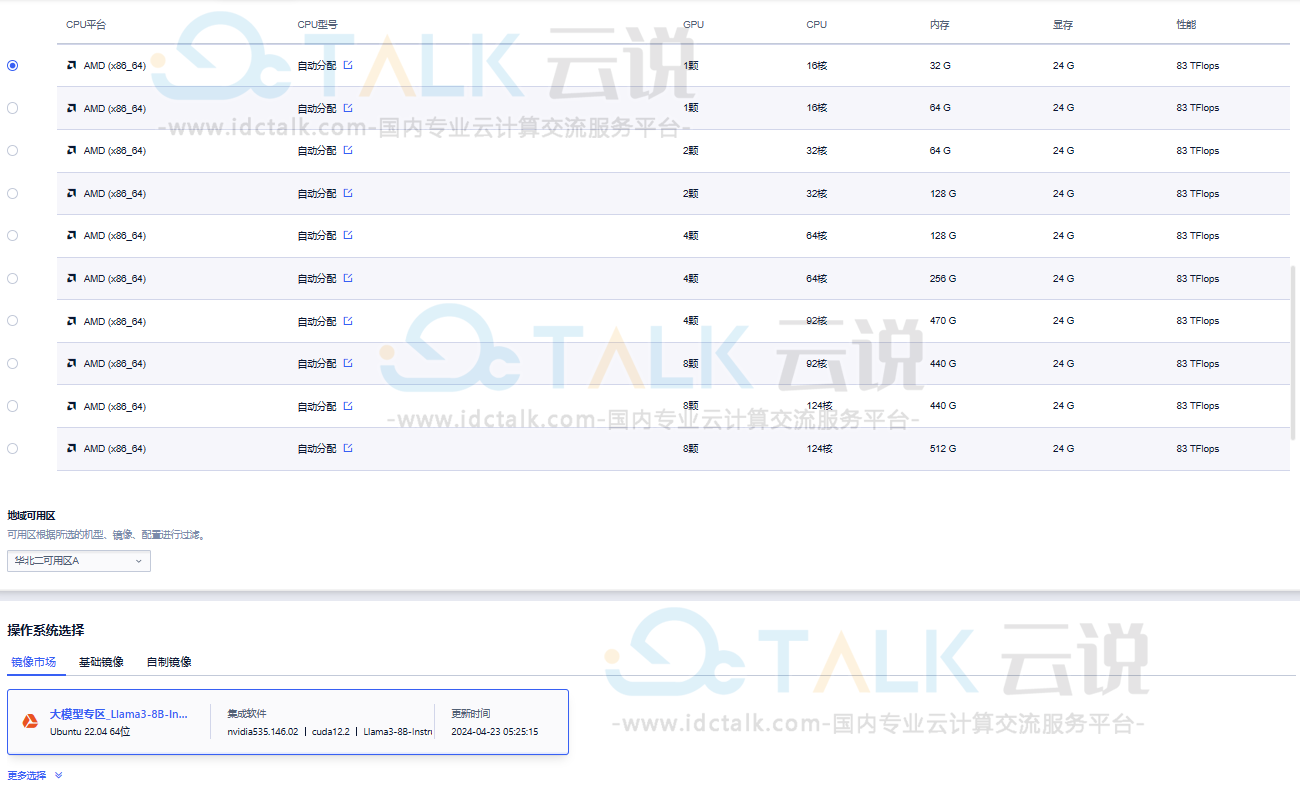
1、登录UCloud官网,进入控制台。
- 机型选择“GPU型”,“高性价比显卡6”,CPU及GPU颗数等详细配置按需选择。
- 最低推荐配置:16核CPU 32G内存1颗高性价比显卡6 GPU。
- 镜像选择“镜像市场”,镜像名称搜索“Llama3”,选择该镜像创建GPU云主机即可。
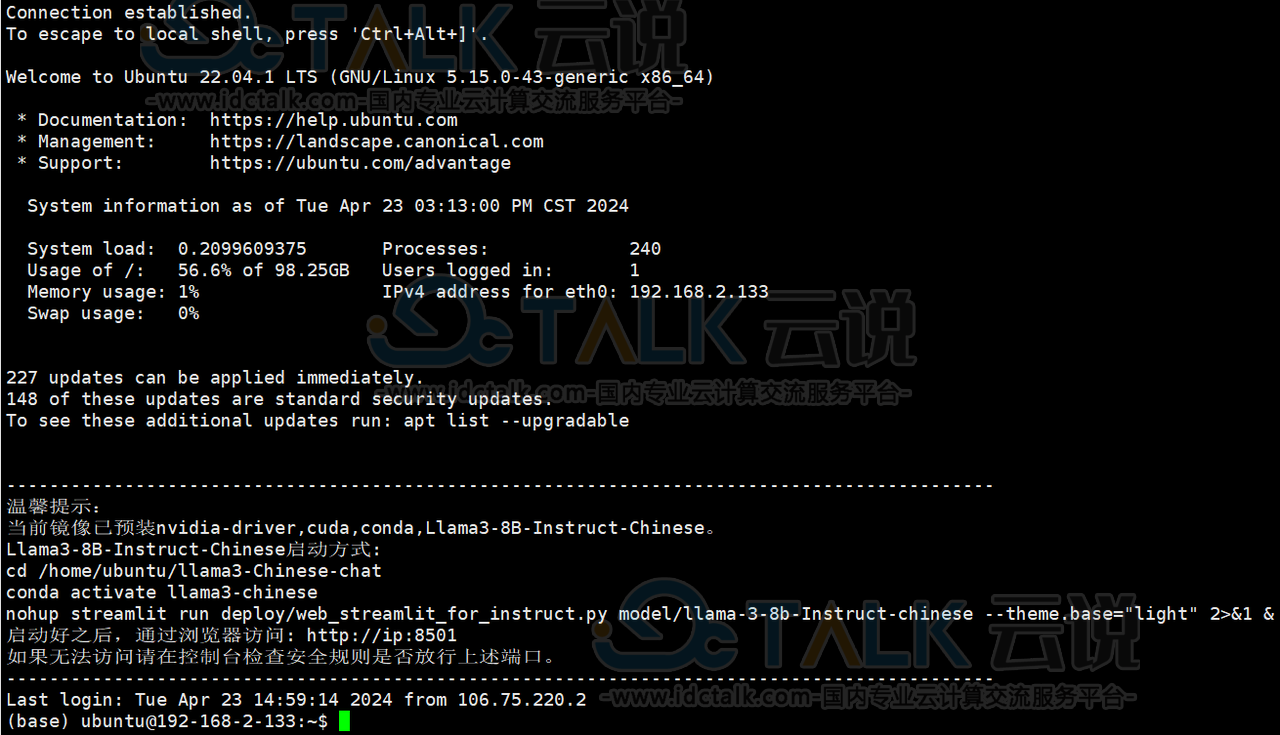
2、GPU云主机创建成功之后,登录GPU云主机。
登录页面如下所示:
web操作页面如下所示: