








































在AIGC的热潮中,向量数据库的重要性不言而喻。作为一项早期主要应用于推荐系统的技术,向量数据库随着 LLM 的兴起而备受瞩目。

什么是向量数据库
向量数据库通常被认为是大模型的“海马体”或“记忆海绵”。它采用向量嵌入方式对非结构化数据(文本、图像和音频等)进行存储和管理。通过使用向量化计算,可以快速查找和检索相似的对象。
向量是 AI 理解世界的通用数据形式,无论是什么模态的数据,机器学习模型接触的都是向量化数据。在 AI 的世界中,处理的所有数据都以向量形式存在。举个例子,“七牛云向量数据库”,在大型模型中会被转化为以下向量形式:
("七牛云", [0.1, 0.1, 0.8, 0.6, ......,0.7, 0.8, 0.8, 0.6]),
("向量", [0.2, 0.3, 0.5, 0.5, ......,0.6, 0.6, 0.2, 0.9]),
("数据库", [0.3, 0.1, 0.4, 0.5, ......,0.6, 0.8, 0.3, 0.1])。
相较于传统数据库,向量数据库以其向量化计算的强大能力,可以高速地处理大规模的复杂数据。同时,向量数据库支持复杂的查询操作,并可轻松扩展到多个节点以处理更大规模的数据。
为什么需要向量数据库
事实上,初始的大型语言模型没有记忆功能,无法记录用户的聊天记录和喜好。因此,它只能根据历史训练数据回答问题,有时会给出与事实相悖的答案。
要解决这个问题,通常有两种方法。
一是通过 Fine-Tuning,根据特定任务,使用小规模数据集来微调模型,让它记住更多信息,类似于给大模型注入长期记忆,但这和人类的长期记忆一样,无法实时更新。
第二种方法是通过 Embedding 的方式,通常利用上下文学习来建立存储能力。相当于在处理数据时,大模型提供帮助,告诉它如何处理这些数据。
但大模型有上下文长度限制,这时候就有了向量数据库。
相当于给大模型外挂了海量“帮助库”,为大语言模型提供外部储存的记忆,让它存储更多信息。这样,当它面对复杂问题和数据时,可以随时从向量数据库中调取信息。
七牛云向量数据库产品进化
要打造一款高效实用的向量数据库,背后所需的核心技术主要包括:向量索引技术、分布式系统架构和硬件加速技术。
在大语言模型崛起之前,向量数据库主要应用于与非结构化数据相关的查询和检索,例如以图搜图、文本检索等。
七牛云最初在“以图搜图”服务中探索向量数据库的应用。结合深度学习检测和特征提取 AI 模型的能力,入库阶段提取海量图像库的语义特征,存储到分布式向量数据库。搜索查询阶段,在图像库进行高效的相似搜索,返回与搜索图像在语义上最相似的多张图像。
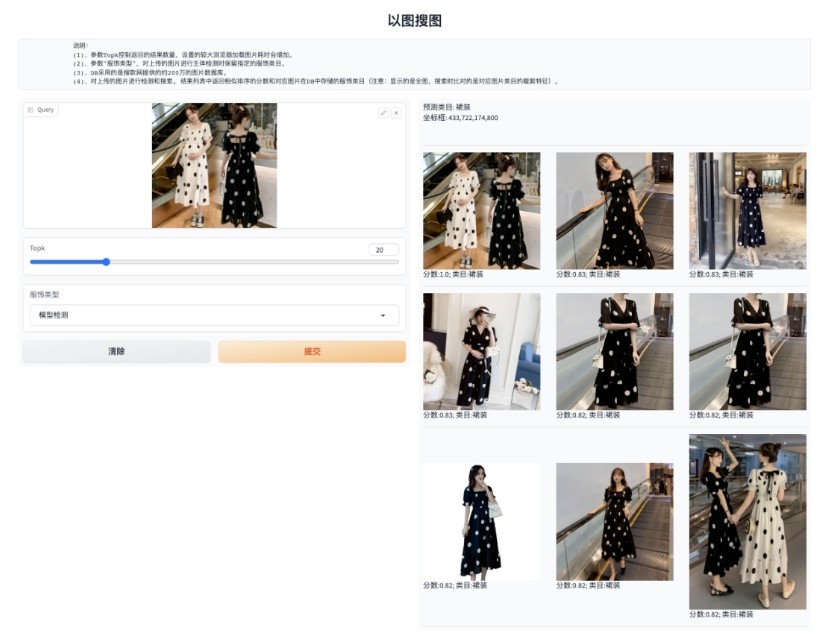
作为云原生分布式向量数据库,七牛云向量数据库可存储、索引和管理海量向量式数据集。

为什么是云原生分布式向量数据库?
向量数据规模庞大,单机无法满足存储要求。分布式系统是计算机程序的集合,这些程序利用多个节点的计算资源来实现共同的目标。云原生架构最大的价值在于为企业提供有效的数据收集、处理和使用能力。
从非结构化数据的预处理、数据存取到向量的持久化,再到结果数据的内容安全,七牛云的全方位技术方案可以提高模型训练和调优的效率。作为扩展插件提供知识增强能力,它为 AIGC 应用提供更丰富、全面的数据处理能力。
随着生成式 AI 技术的不断发展,七牛云将在更多场景中发挥重要作用,为 AIGC 开发者提供一站式支持。



