







































近些年,开源大语言模型(LLM)进步飞快,例如LLaMA和Vicuna等模型在各种语言理解、生成任务上展现了极佳的水平。但是,当它们面对更高级别的任务,例如根据用户指令使用外部工具(API)时,仍然有些力不从心。
为了解决这个问题,面壁智能联合来自TsinghuaNLP、耶鲁、人大、腾讯、知乎的研究人员推出ToolLLM工具学习框架,加入OpenBMB大模型工具体系“全家桶”。ToolLLM 框架包括如何获取高质量工具学习训练数据、模型训练代码和模型自动评测的全流程。作者构建了ToolBench 数据集,该数据集囊括16464个真实世界API。
ToolBench 的构建完全由最新的ChatGPT(gpt-3.5-turbo-16k)自动化完成,无需人工标注。在ToolBench上训练出来的模型具备极强的泛化能力,能够直接被应用到新的API上,无须额外训练。下表列出了ToolBench与之前相关工作的对比情况。ToolBench 不仅在多工具混合使用场景独一无二,且在真实 API 数量上也一骑绝尘。
基于ToolBench,作者微调LLaMA 7B模型并得到了具备工具使用能力的 ToolLLaMA。由于训练数据中存在十分多样的工具与指令,ToolLLaMA学习到了非常强的泛化能力,能在测试中处理一些在训练期间未见过的新任务、新工具。为了验证ToolLLaMA的泛化能力,作者进行了三个级别的测试:
1. 单一工具指令测试(I1):评测模型解决面向单工具的在训练中未学习过的新指令
2. 类别内多工具指令测试(I2):评测模型如何处理已经再训练中学习过的类别下的多种工具的新指令
3. 集合内多工具指令测试(I3):考查模型如何处理来自不同类别的工具的新指令
作者选择了两个已经针对通用指令微调的 LLaMA 变体 Vicuna 和 Alpaca 以及OpenAI的ChatGPT 和 Text-Davinci-003 作为 baseline。对所有这些模型应用了更加先进的 DFSDT 推理算法,此外对 ChatGPT 应用了 ReACT。在计算 win rate 时,将每个模型与 ChatGPT-ReACT 进行比较。下面两幅图总结了 ToolLLaMA 模型和其他模型比较结果:
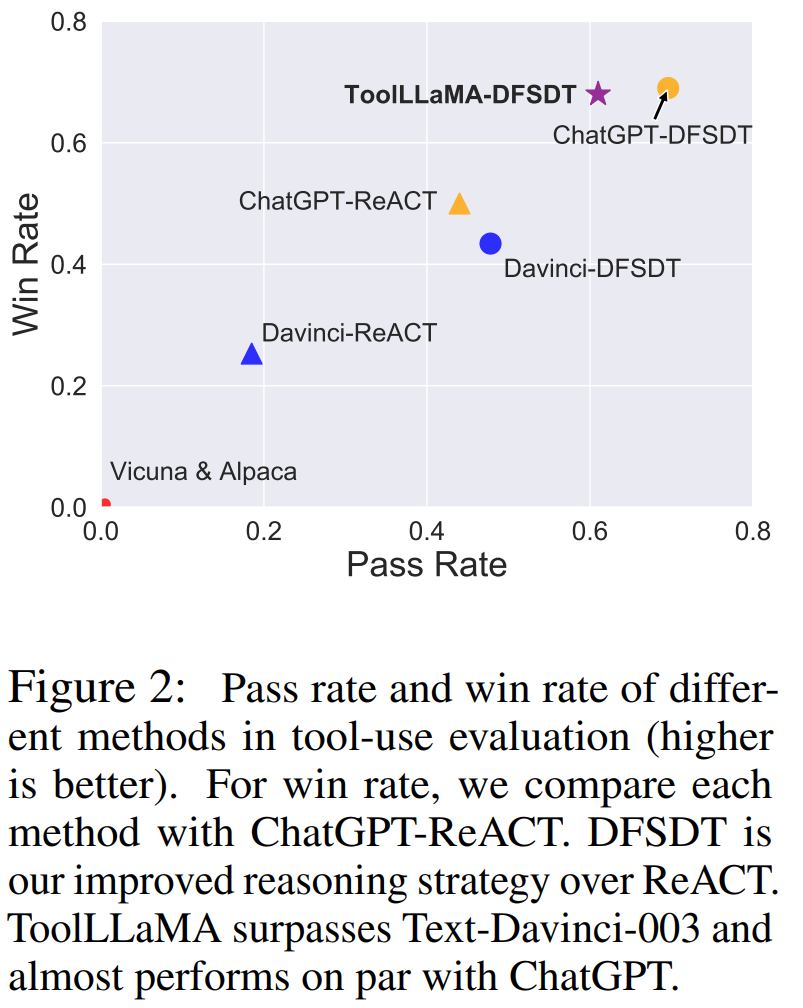
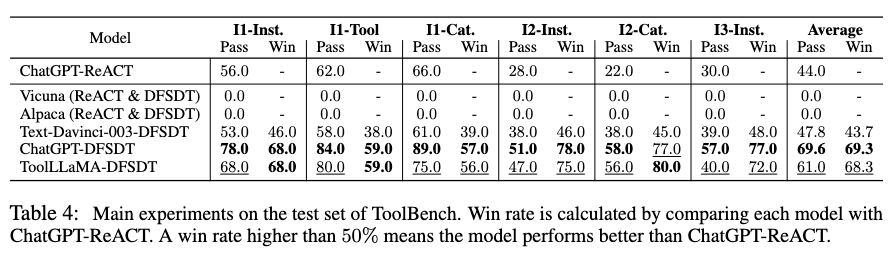
根据上图显示,ToolLLaMA 在 pass rate 和 win rate 上显著优于传统的工具使用方法 ChatGPT-ReACT,展现出优越的泛化能力,能够很容易地泛化到没有见过的新工具上,这对于用户定义新 API 并让 ToolLLaMA 高效兼容新 API 具有十分重要的意义。此外,作者发现 ToolLLaMA 性能已经十分接近 ChatGPT,并且远超 Davinci, Alpaca, Vicuna 等 baseline。
ToolLLM 框架的推出,有助于促进开源语言模型更好地使用各种工具,增强其复杂场景下推理能力。该创新将有助于研究人员更深入地探索 LLMs 的能力边界,也为更广泛的应用场景敞开了大门。目前ToolLLM的所有相关代码均已开源。


