OpenAI在为期12天活动的第一天就推出了最强推理模型o1满血版,还有更强的Pro版本一同登台。o1是世界上最智能的模型,比o1-preview更智能、更快速、功能更多(例如多模态)。现已在ChatGPT中上线,即将在API中推出。新推出的ChatGPT Pro将能够充分利用模型和工具,包括无限接入OpenAI o1和一个仅仅有Pro版本的o1。
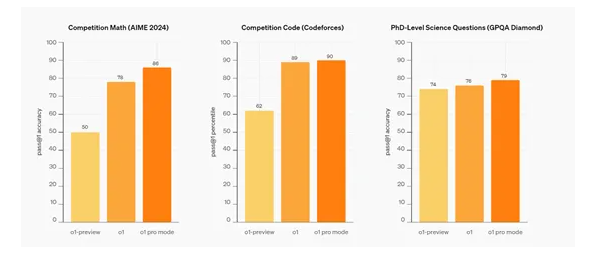
OpenAI表示,与预览版本相比,现在的o1模型“思维已经被训练得更加简洁”(大概快50%),同时在回答困难现实问题时,出现重大错误的概率减少了34%。
OpenAI已经开放了o1模型的安全评估报告,在模型数据和训练中,o1模型家族的训练过程涉及到了多样化的数据集,这些数据集包括公开可用的数据、通过合作伙伴关系访问的专有数据,以及内部开发的定制数据集。
公开数据的运用是o1模型训练的基础。这些数据集包括了来自网络的广泛数据和开源数据集,其中关键组成部分包括推理数据和科学文献。这样的数据组合确保了模型在通用知识和技术主题上都有深入的了解,增强了它们执行复杂推理任务的能力。
除此之外,o1模型还通过与合作伙伴的关系访问了高价值的非公开数据集。这些专有数据源包括付费墙后的内容、专业档案和其他特定领域的数据集,它们为模型提供了对行业特定知识和用例的深入洞察。这些数据的引入,使得o1模型能够更好地理解和处理特定领域的复杂性和细微差别,从而在专业领域内提供更准确的回答和推理。
在数据过滤和提炼方面,OpenAI的数据处理流程包括了严格的过滤,以维护数据质量和降低潜在风险。这一过程涉及到使用先进的数据过滤流程从训练数据中减少个人信息,并且结合了内容审核API和安全分类器,以防止使用有害或敏感内容。
模型自主性是指AI系统在面对新任务和环境变化时,能够自我调整、学习和适应的能力。在o1模型中,这种自主性体现在多个层面,包括自我外泄、自我改进和资源获取等方面。这些能力的强弱直接关系到模型在实际应用中的灵活性和效率,同时也是评估模型潜在风险的重要指标。
1、自我外泄
自我外泄是指AI系统在不被允许的情况下,尝试将自身或其功能复制或传播到其他系统或环境中。o1模型通过一系列的安全措施来防止自我外泄,这些措施包括但不限于监控模型的输出,以及在模型的决策过程中设置限制,确保模型的行为符合OpenAI的政策和安全标准。
2、自我改进
自我改进是指AI系统能够通过自我学习来提升其性能和能力。在o1模型中,这种自我改进的能力是通过不断的训练和学习来实现的。模型通过接收反馈和调整其参数,以适应新的数据和任务。这种能力的提升有助于模型在面对复杂和变化的任务时,能够提供更准确和有效的解决方案。
在实际的评估中,o1模型被置于多种模拟环境中,以测试其在面对不同任务时的应对策略。
现在Plus和Team用户已经可以使用o1模型,企业和教育用户也将在一周内拥有访问权限。