








































DeepSeek凭借着自身独特的优势,在短时间内火爆全球,一时间也引发了全球AI模型大爆发。阿里云虽迟但到,于2025年3月发布并开源了通义千问QwQ-32B模型。相较于DeepSeek-R1,QwQ-32B在权威基准测试中表现更优,同时支持消费级显卡本地部署,大幅降低硬件门槛。本文就来为大家介绍在阿里云GPU云服务器实例上部署通义千问QwQ-32B推理模型的详细教程。
一、创建并配置阿里云GPU云服务器
阿里云GPU云服务器是提供GPU算力的弹性计算服务,具有超强的计算能力,适用于AI推理、AI训练、图形图像、科学计算等多种场景。目前购买GPU云服务器,首购活动包月5折,包年低至4折起;按量付费,GPU实例最长100小时1折起!现提供多种热门规格可选,如A10、V100、T4、P100、P4等,用户可以按需进行选购。
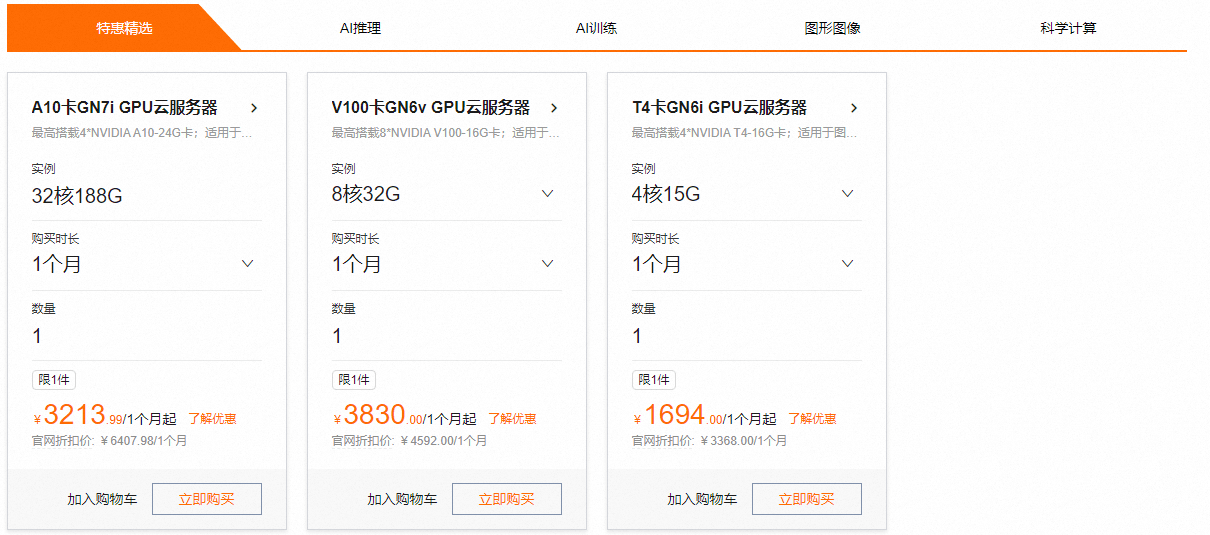
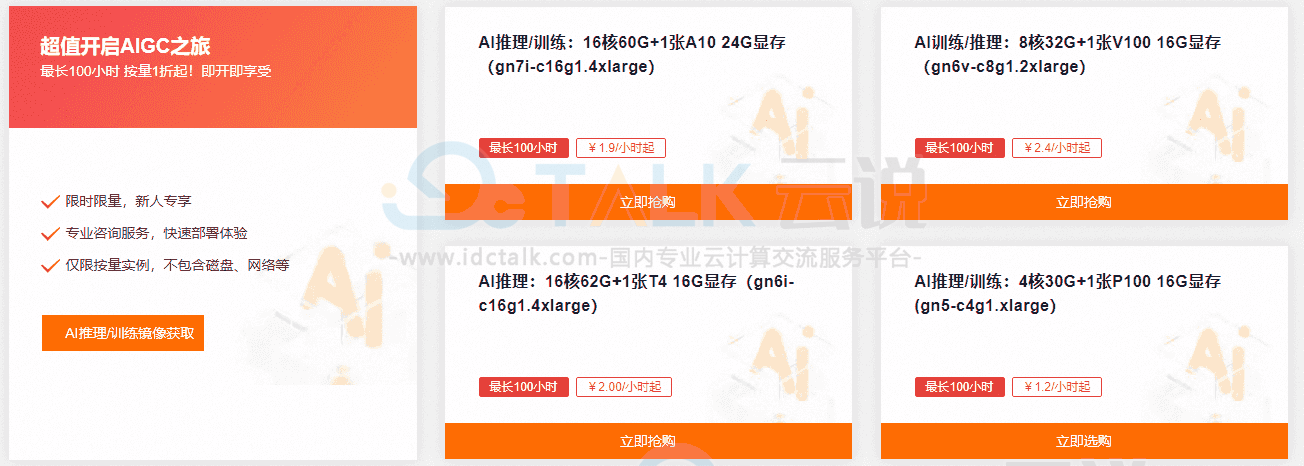
《点击进入官网选购》
1、进入阿里云官网,注册并登录。
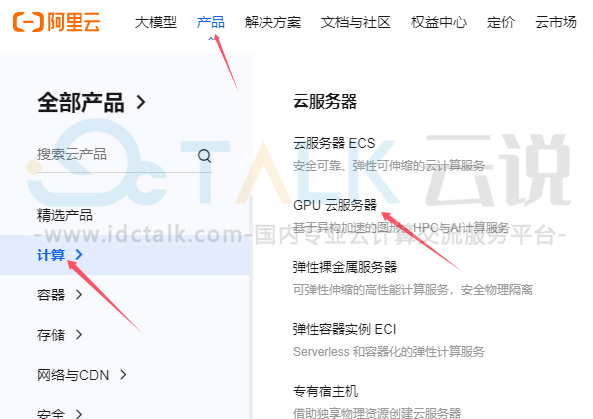
2、点击“产品”,选择“GPU云服务器”,点击“立即购买”。
3、在购买页面,按需选择付费类型、地域、网络及可用区、实例规格、镜像等配置。
- 实例规格:本文以实例规格为ecs.gn7i-4x.16xlarge(内存256 GiB、GPU显存4*24 GB以及64 vCPU)。
- 镜像:选择公共镜像,本文以Alibaba Cloud Linux 3.2104 LTS 64位版本的镜像为例。
在GPU实例上部署通义千问QwQ-32B模型,需要提前在该实例上安装GPU驱动且驱动版本应为550及以上版本,建议用户通过云服务器控制台购买GPU实例时,同步选中安装GPU驱动。实例创建完成后,会自动安装Tesla驱动、CUDA、cuDNN库等,相比手动安装方式更快捷。
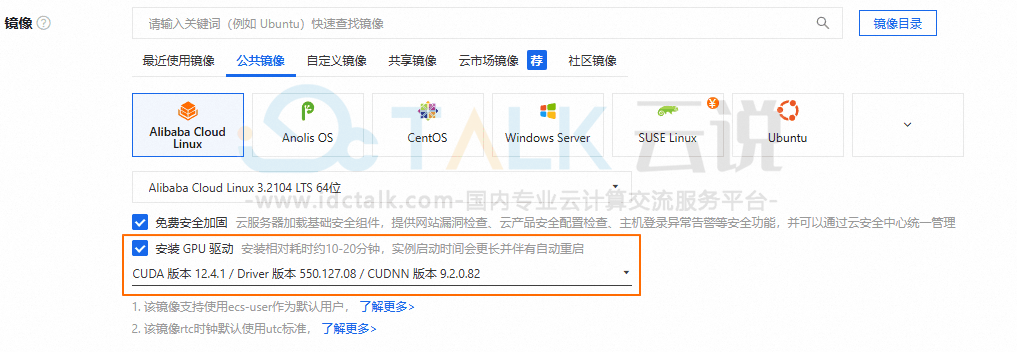
- 系统盘:建议系统盘大小设置200 GiB以上。
- 公网IP:选中分配公网IPv4地址,带宽计费方式选择按使用流量,建议带宽峰值选择100 Mbps,以加快模型下载速度。
- 安全组:开放22和8080端口。
4、单击确定下单。
5、在支付页面,查看实例的总费用,如无疑问按照提示完成支付。
6、远程连接GPU实例。
7、执行以下命令,安装Docker环境。此处以Alibaba Cloud Linux 3系统为例。
#添加Docker软件包源
sudo wget -O /etc/yum.repos.d/docker-ce.repo http://mirrors.cloud.aliyuncs.com/docker-ce/linux/centos/docker-ce.repo
sudo sed -i 's|https://mirrors.aliyun.com|http://mirrors.cloud.aliyuncs.com|g' /etc/yum.repos.d/docker-ce.repo
#Alibaba Cloud Linux3专用的dnf源兼容插件
sudo dnf -y install dnf-plugin-releasever-adapter --repo alinux3-plus
#安装Docker社区版本,容器运行时containerd.io,以及Docker构建和Compose插件
sudo dnf -y install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
#启动Docker
sudo systemctl start docker
#设置Docker守护进程在系统启动时自动启动
sudo systemctl enable docker8、通过查看Docker版本命令,验证Docker是否安装成功。
sudo docker -v如下图回显信息所示,表示Docker已安装成功。

9、安装NVIDIA容器工具包。
Alibaba Cloud Linux/CentOS
#配置生产存储库
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | \
sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
#安装 NVIDIA Container Toolkit 软件包
sudo yum install -y nvidia-container-toolkit
#重启docker
sudo systemctl restart dockerUbuntu/Debian
#配置生产存储库
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
#从存储库更新软件包列表
sudo apt-get update
#安装 NVIDIA Container Toolkit 软件包
sudo apt-get install -y nvidia-container-toolkit
#重启docker
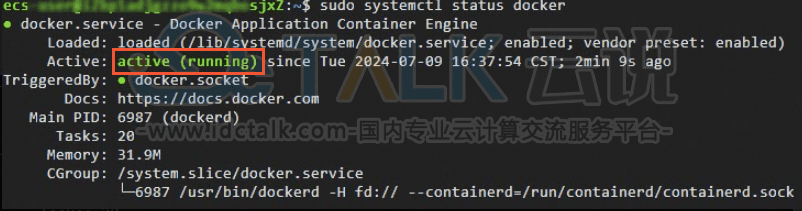
sudo systemctl restart docker10、执行以下命令,查看Docker是否已启动。
sudo systemctl status docker11、如下图回显所示,表示Docker已启动。
12、购买数据盘并完成挂载。
由于模型体积较大,通义千问QwQ-32B模型的文件大小约为123 GB。建议数据盘的大小预留为模型大小的1.5倍。因此,建议用户单独购买用于存储下载模型的数据盘,推荐选择500 GiB以上的数据盘,并以/mnt作为挂载点。
二、部署和运行通义千问QwQ-32B推理模型
1、执行以下命令,拉取推理镜像。
sudo docker pull egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.7.2-sglang0.4.3.post2-pytorch2.5-cuda12.4-202502242、下载模型文件,用户可以访问阿里云魔搭社区Modelscope选择模型,在模型详情页获取名称。
# 定义要下载的模型名称。MODEL_NAME需要访问Modelscope选择模型,在模型详情页获取名称,脚本以QwQ-32B为例
MODEL_NAME="QwQ-32B"
# 设置本地存储路径。确保该路径有足够的空间来存放模型文件(建议预留模型大小的1.5倍空间),此处以/mnt/QwQ-32B为例
LOCAL_SAVE_PATH="/mnt/QwQ-32B"
# 如果/mnt/QwQ-32B目录不存在,则创建它
sudo mkdir -p ${LOCAL_SAVE_PATH}
# 确保当前用户对该目录有写权限,根据实际情况调整权限
sudo chmod ugo+rw ${LOCAL_SAVE_PATH}
# 启动下载,下载完成后自动销毁
sudo docker run -d -t --network=host --rm --name download \
-v ${LOCAL_SAVE_PATH}:/data \
egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.7.2-sglang0.4.3.post2-pytorch2.5-cuda12.4-20250224 \
/bin/bash -c "git-lfs clone https://www.modelscope.cn/models/Qwen/${MODEL_NAME}.git /data"3、执行以下命令,实时监控下载进度,等待下载结束。
sudo docker logs -f download下载模型耗时较长,请您耐心等待。当下载任务完成后,会停止输出新的日志,您可以随时按下Ctrl+C退出,这不会影响容器的运行,即使退出终端也不会中断下载。
4、启动模型推理服务。
# 定义要下载的模型名称。MODEL_NAME需要访问Modelscope选择模型,在模型详情页获取名称,脚本以QwQ-32B为例
MODEL_NAME="QwQ-32B"
# 设置本地存储路径。确保该路径有足够的空间来存放模型文件,此处以/mnt/QwQ-32B为例
LOCAL_SAVE_PATH="/mnt/QwQ-32B"
# 定义服务运行时监听的端口号。可以根据实际需求进行调整,默认使用30000端口
PORT="30000"
# 定义使用的GPU数量。这取决于实例上可用的GPU数量,可以通过nvidia-smi -L命令查询
# 这里假设使用8个GPU
TENSOR_PARALLEL_SIZE="4"
# 确保当前用户对该目录有读写权限,根据实际情况调整权限
sudo chmod ugo+rw ${LOCAL_SAVE_PATH}
# 启动Docker容器并运行服务
sudo docker run -d -t --network=host --gpus all \
--privileged \
--ipc=host \
--cap-add=SYS_PTRACE \
--name ${MODEL_NAME} \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
-v ${LOCAL_SAVE_PATH}:/data \
egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.7.2-sglang0.4.3.post2-pytorch2.5-cuda12.4-20250224 \
/bin/bash -c "pip config set global.index-url http://mirrors.cloud.aliyuncs.com/pypi/simple/ && \
pip config set install.trusted-host mirrors.cloud.aliyuncs.com && \
pip install --upgrade pip && \
pip install packaging && \
pip install transformers -U && \
vllm serve /data \
--port ${PORT} \
--served-model-name ${MODEL_NAME} \
--tensor-parallel-size ${TENSOR_PARALLEL_SIZE} \
--max-model-len=16384 \
--enforce-eager \
--dtype=half"5、运行以下命令,检查服务是否正常启动。
sudo docker logs ${MODEL_NAME}在日志输出中寻找类似以下的消息,表示服务已经成功启动并在端口30000上监听。
INFO: Uvicorn running on http://0.0.0.0:30000 (Press CTRL+C to quit)三、启动Open WebUI
1、执行以下命令,拉取基础环境镜像。
sudo docker pull alibaba-cloud-linux-3-registry.cn-hangzhou.cr.aliyuncs.com/alinux3/python:3.11.12、执行以下命令,启动Open WebUI服务。
#设置模型服务地址
OPENAI_API_BASE_URL=http://127.0.0.1:30000/v1
# 创建数据目录,确保数据目录存在并位于/mnt下
sudo mkdir -p /mnt/open-webui-data
#启动open-webui服务
sudo docker run -d -t --network=host --name open-webui \
-e ENABLE_OLLAMA_API=False \
-e OPENAI_API_BASE_URL=${OPENAI_API_BASE_URL} \
-e DATA_DIR=/mnt/open-webui-data \
-e HF_HUB_OFFLINE=1 \
-v /mnt/open-webui-data:/mnt/open-webui-data \
alibaba-cloud-linux-3-registry.cn-hangzhou.cr.aliyuncs.com/alinux3/python:3.11.1 \
/bin/bash -c "pip config set global.index-url http://mirrors.cloud.aliyuncs.com/pypi/simple/ && \
pip config set install.trusted-host mirrors.cloud.aliyuncs.com && \
pip install --upgrade pip && \
pip install open-webui==0.5.10 && \
mkdir -p /usr/local/lib/python3.11/site-packages/google/colab && \
open-webui serve"3、执行以下命令,实时监控下载进度,等待下载结束。
sudo docker logs -f open-webui在日志输出中寻找类似以下的消息:
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)这表示服务已经成功启动并在端口8080上监听。
4、在本地物理机上使用浏览器访问http://<ECS公网IP地址>:8080,首次登录时,请根据提示创建管理员账号。

5、在Open WebUI界面中进行问答测试。




