








































近日,腾讯优图实验室联合厦门大学在新建的评测基准MME上首次对全球范围内MLLM模型进行了全面定量评测并公布了16个排行榜,包含感知、认知两个总榜单以及14个子榜单。昆仑万维天工大模型多模态团队的Skywork-MM模型位列综合榜单第一,其中,感知榜单排名第一、认知榜单排名第二。
综合榜单排名第一:
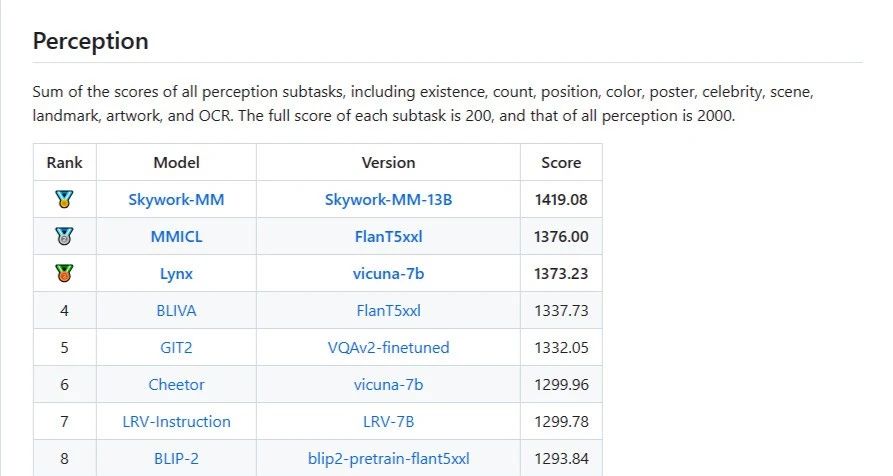
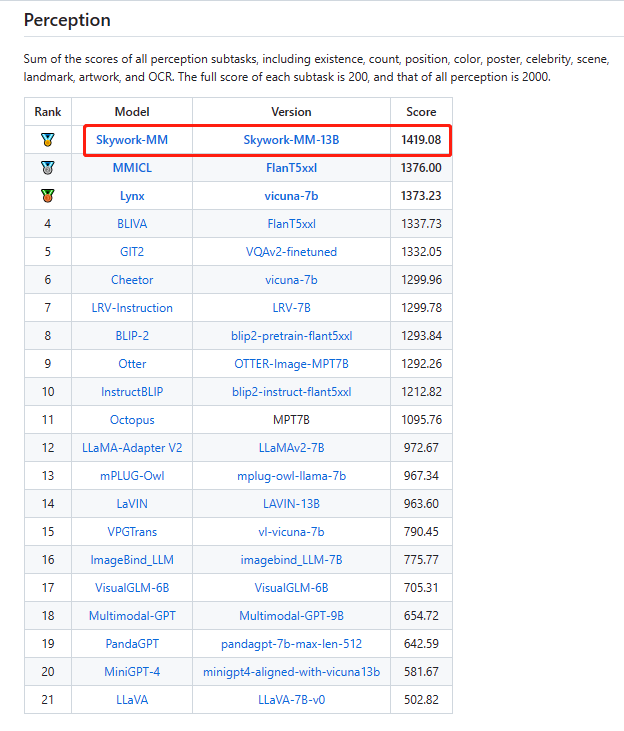
感知榜单排名第一:
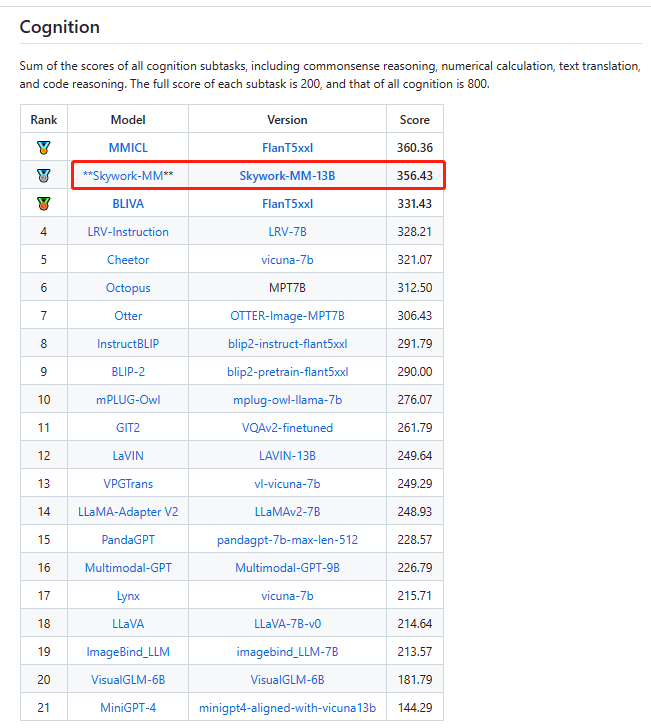
认知榜单排名第二:
随着文本大模型的快速发展,构建具有多模态理解能力的多模态语言模型是行业大势所趋。多模态模型展现了较好的多模态信息理解能力,但依然存在一些问题,如现有的多模态语言模型存在较为严重的幻觉问题,对于大多数问题,模型都倾向于回答“yes”,同时,跨语言能力较弱,在中文场景中对问题的回答不尽如人意,有时甚至会直接回复英文。基于以上问题,昆仑万维天工大模型多模态团队给出了自己的解决方案——Skywork-MM。
在昆仑万维天工大模型多模态团队最新一篇论文中可知,在数据侧,为了解决幻觉问题,天工AI助手团队构造了更加多样和精细的微调数据,加强大模型对于图片特征的理解能力,增强多模态语言模型的指令跟随能力并减少“幻觉”,Skywork-MM在减少幻觉方面提升显著:
此外,Skywork-MM通过适当的数据构造,增强了中文的指令追随能力、中文相关场景的识别能力,减轻了文化偏差对于多模态理解的影响。
在模型侧,在模型设计上团队将视觉模型和大语言模型完全冻结,保持视觉模型在前置CLIP训练中学习到的视觉特征不损失,大语言模型的语言能力不损失。同时为了更好的关联视觉特征和语言特征,模型整体包含了一个可学习的视觉特征采样器和语言模型的LoRA适配器。
Skywork-MM模型的训练上,分为两个阶段,第一阶段使用双语的大规模图文pair数据进行图像概念和语言概念的关联学习;第二阶段使用多模态微调数据进行指令微调。最终,Skywork-MM实际上使用的图文数据并不多(约50M),远远小于其他现有的MLLM使用的图文数据量(大于100M),却在测评中取得了综合排名第一的优异成绩,证明了昆仑万维在训练多模态大模型方面找到了合适的技术路径,团队实力不俗。
未来,昆仑万维将加速提升多模态能力,将研究、研发与产品相结合,支撑旗下AI产品朝着多模态方向发展,如近期推出的天工AI搜索在具备良好的多模态能力后将助力用户获得颠覆式搜索体验。可以预见,多模态能力将助力昆仑万维在AGI与AIGC的研发、产品落地、商业化进程中获得领先业内的显著优势,在广告营销、游戏、娱乐、社交、咨询、办公、金融、能源等众多行业落地应用。



